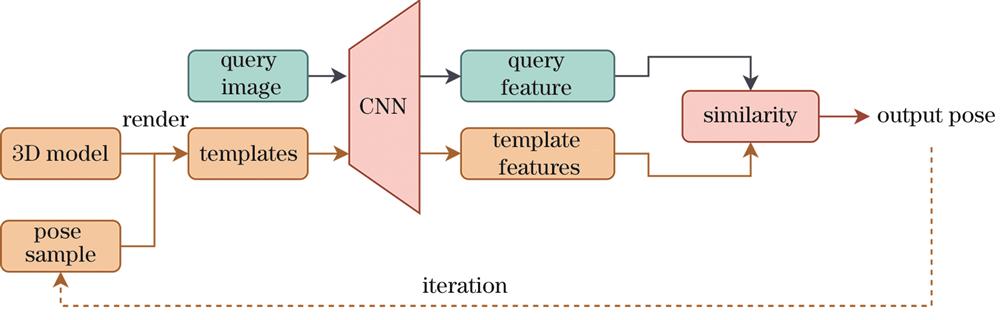
Fig. 1. Algorithm framework
Fig. 2. Attention lightweight convolutional submodule
Fig. 3. Example of angle sampling
Fig. 4. Examples. (a) LINEMOD
[36]; (b) Occlusion-LINEMOD
[37] Fig. 5. Comparison of Blender and PyTorch3D rendering results
Fig. 6. Comparison of qualitative experiments before and after optimization
算法1:迭代优化过程的渲染视角采样 |
|---|
输入:次采样间隔的点集,边集,当前最优位姿对应点 输出:次采样间隔的点集 |
|---|
For in : If in Then .append() For in :
| End |
|
Table 0. [in Chinese]
| Block name | Input channel | Output channel | Kernel size | Expand channel |
|---|
| Conv | 3 | 32 | 3 | – | | BaseBlock | 32 | 16 | 3 | – | | BaseBlock | 16 | 24 | 3 | 96 | | BaseBlock | 24 | 24 | 3 | 144 | | BaseBlock | 24 | 40 | 5 | 144 | | BaseBlock | 40 | 40 | 5 | 240 | | Conv | 40 | 16 | 1 | – |
|
Table 1. Structure of proposed model
| Network | Running time /min | Inference time /ms | Number of parameters /106 | Memory size /MB |
|---|
| BaseNet[25-26] | 0.31 | 5.68 | 0.024 | 0.048 | | ResNet[23] | 1.15 | 1126.20 | 24.036 | 92.053 | | Proposed | 0.74 | 48.37 | 0.043 | 20.464 |
|
Table 2. Comparison of model parameter quantity
| Split No. | Train | Test | Unseen object name |
|---|
| 1 | 9954 | 15038 | Ape,benchvise,camera,can | | 2 | 9928 | 15064 | Cat,driller,duck,eggbox | | 3 | 8850 | 16142 | Glue,holepuncher,iron,lamp,phone |
|
Table 3. Details of datasets
| Method | Render | Seen LM | Seen O-LM | Unseen LM | Unseen O-LM |
|---|
| Wohlhart’s[25] | Blender | 95.2 | 19.6 | 13.3 | 8.2 | | Balntas’s[26] | Blender | 96.3 | 18.3 | 11.5 | 7.1 | | Template-pose[23] | Blender | 99.3 | 77.3 | 94.4 | 71.4 | | Template-pose[23] | PyTorch3D | 98.5 | 75.7 | 95.7 | 70.3 | | Proposed | PyTorch3D | 97.6 | 80.0 | 98.1 | 74.8 |
|
Table 4. Comparison of Acc15 on LM and O-LM datasets
| Split No. | Method | Render | Seen LM | Seen O-LM | Unseen LM | Unseen O-LM | Average |
|---|
| 2 | Template-pose | Blender | 99.0 | 84.1 | 97.4 | 72.7 | 88.3 | | 2 | Template-pose | PyTorch3D | 97.0 | 77.9 | 96.6 | 70.5 | 85.5 | | 2 | Proposed | PyTorch3D | 96.8 | 81.9 | 98.8 | 76.5 | 88.5 | | 3 | Template-pose | Blender | 99.2 | 76.8 | 88.7 | 85.3 | 87.5 | | 3 | Template-pose | PyTorch3D | 99.0 | 75.2 | 85.2 | 78.3 | 84.4 | | 3 | Proposed | PyTorch3D | 99.2 | 78.4 | 88.3 | 88.3 | 88.6 |
|
Table 5. Repeated experiments with LM and O-LM datasets
| Condition | Seen LM | Seen O-LM | Unseen LM | Unseen O-LM |
|---|
| Without iteration | 4.70 | 11.45 | 5.57 | 20.94 | | With iteration | 4.16 | 11.18 | 4.74 | 20.47 |
|
Table 6. Comparison of iterative optimization
| Condition | Seen LM | Seen O-LM | Unseen LM | Unseen O-LM | Average |
|---|
| With SE | 99.2 | 78.4 | 88.3 | 88.3 | 88.6 | | Without SE | 99.1 | 77.2 | 86.6 | 86.8 | 87.4 |
|
Table 7. Attention mechanism ablation experiment
| Condition | Seen LM /% | Seen O-LM /% | Unseen LM /% | Unseen O-LM /% | Average /% | Inference time /ms |
|---|
| With DW | 99.2 | 78.4 | 88.3 | 88.3 | 88.6 | 48.37 | Without DW | 97.4 | 70.0 | 62.5 | 43.6 | 68.4 | 669.25 |
|
Table 8. Deep separable convolutional ablation experiment