 AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence

Yan Guo, Hong-Chen Liu, Fu-Jiang Liu, Wei-Hua Lin, Quan-Sen Shao, Jun-Shun Su. Chinese named entity recognition with multi-network fusion of multi-scale lexical information[J]. Journal of Electronic Science and Technology, 2024, 22(4): 100287
- Journal of Electronic Science and Technology
- Vol. 22, Issue 4, 100287 (2024)
Note: This section is automatically generated by AI . The website and platform operators shall not be liable for any commercial or legal consequences arising from your use of AI generated content on this website. Please be aware of this.
Abstract
Keywords
1 Introduction
Named entity recognition (NER) is a subtask in information extraction and a key task in natural language processing (NLP). Its main role is to filter out specific categories of entities from the huge amount of unstructured data, which usually include names of people, places, organizations, and professional terms. Nowadays, NER techniques are widely used in tasks such as information extraction [1], question-answer systems [2], machine translation [3], and knowledge graph construction [4]. In NLP tasks, downstream tasks usually rely on NER to provide key information in the text, and the performance of NER can significantly affect the accuracy of downstream tasks.
The essential task of NER is a sequence annotation problem, and after the rise of machine learning, many studies have shown [5–9] that character-level entity recognition achieves notable results. Most NER tasks were initially studied in the context of English, where word boundaries are easily identified due to the presence of delimiters between words. This characteristic provides clear boundary markers for entities, making entity boundary recognition relatively straightforward. However, with the development of information technology in China, Chinese named entity recognition (CNER) has gained increasing attention. In contrast to typical English NER tasks, CNER faces unique challenges due to the absence of word delimiters, such as spaces, which are used in languages like English to mark word boundaries. This characteristic of the Chinese language leads to boundary ambiguity and difficulty in identifying entities. For example, in “计算机技术系” (Department of Computer Technology), “计算机技术” (Computer Technology) is a compound word with unclear boundaries. Furthermore, the existence of a large number of polysemous words in Chinese requires NER models to have stronger contextual understanding to accurately classify entities. Given the unique characteristics and challenges of CNER, a growing number of approaches have been proposed. Among the most mainstream methods is the application of pre-trained models combined with downstream tasks for CNER. Pre-trained models, by conducting language modeling training on large-scale unlabeled corpora, capture rich linguistic knowledge and contextual relationships. When applied to downstream tasks, pre-trained models serve as the base, and through fine-tuning with a small amount of labeled data, they can quickly adapt to the specific needs of the task. A representative approach is the BERT-BiLSTM-CRF model, which uses Bidirectional Encoder Representations from Transformers (BERT) as the pre-trained model and bi-directional long short-term memory (BiLSTM) as the downstream neural network. While BERT and BiLSTM enhance the contextual representation of the text and improve CNER recognition accuracy to some extent, this method also has certain limitations. BiLSTM performs well in handling short-range dependencies, but struggles with long texts or long-distance dependencies. Moreover, due to the lack of clear word boundaries in the Chinese language, this method does not account for word boundary information, which limits its ability to capture some latent contextual information. As a result, it may fail to accurately recognize compound words or multi-word entities. Introducing vocabulary into the CNER task, a large number of studies and experimental results show that this approach can improve the recognition performance of entity recognition very well [10–15]. It is worth noting that the approach which combines pre-trained models with downstream tasks is highly recommended. However, the key challenge lies in designing appropriate downstream neural networks to adapt to the specific entity recognition tasks, which requires further research.
The techniques for NER can be classified into three categories: Rule-based methods, machine learning combined with statistical methods, and deep learning-based methods. In the early stages of NER, there was substantial reliance on rules and manually designed features. Researchers identified named entities using techniques such as regular expressions and dictionary-based methods; however, this approach faces challenges in generalizing to new entities and domains.
With the rise of machine learning in the field of NLP, statistical methods started to be used in NER and became mainstream, such as support vector machines (SVMs), conditional random fields (CRFs), maximum entropy Markov models (MEMMs), hidden Markov models (HMMs), and decision tree classifier (DTC) [16]. In the realm of entity recognition tasks, CRF [17], a concept co-proposed by Lafferty, McCallum, and Pereira, remains widely utilized. This approach highlights certain limitations of traditional models, such as HMM, particularly in terms of feature representation and label dependencies. CRF addresses some of these deficiencies by modeling the conditional distributions of output label sequences given input sequences, as well as by incorporating the global feature context to model dependencies between labels. Numerous subsequent validations have consistently demonstrated the superiority of this method. For instance, Li et al. [18] proposed a rule based on decision tree generation in conjunction with CRF, combining it with clinical knowledge rules for entity recognition in medical charts. This integrated approach yielded improved results, making the method more applicable in clinical environments. Similarly, Sobhana et al. [19] developed a geo-textual NER system based on CRF, utilizing different contextual information of words and various features to predict various named entity classes. However, relying solely on statistical methods still has its shortcomings, including challenges in rule design, internal and external feature construction, and over-reliance on feature representations in the corpus, constant template adjustments continue to necessitate significant human costs and time overheads.
The advent of deep learning has led to the widespread adoption of deep learning-based methods for NER. These approaches leverage deep neural networks to autonomously learn feature representations from the text, eliminating the need for manual feature design. This advancement has enhanced the performance of NER tasks, allowing for notable improvements and achieving commendable results in the field of NER. Hochreiter et al. [5] were the first to propose the long short-term memory (LSTM) architecture. LSTM is a type of recurrent neural network (RNN) that integrates gating mechanisms, providing the network with the ability to selectively control the flow of information. This feature allows the network to more effectively capture and retain important features within sequences, addressing challenges such as gradient vanishing and handling long-range dependencies that are common issues in traditional RNN. Schuster et al. [6] introduced a bidirectional RNN architecture, capable of considering both past and future contextual information at each time step, resulting in more comprehensive capture of dependencies in sequences. This bidirectional approach can outperform unidirectional RNN in certain cases. Nowadays, BiLSTM, a variant of this architecture, is extensively utilized in NER tasks. In comparison to LSTM, BiLSTM retains the gating mechanism while providing richer feature representations, better understanding of the context, and consideration of both past and future information. In addition to RNNs, other deep learning-based methods such as convolutional neural network (CNN) and attention mechanisms are also applied to NER. Strubell et al. [20] introduced a method based on the iterated dilated convolutional neural network (IDCNN) to address the trade-off between speed and accuracy in entity recognition tasks. Traditional RNNs face challenges in leveraging the parallel computing power of graphics processing unit (GPU) for complex structures, leading to slower operation speeds. The proposed method achieves both high accuracy and faster operation by expanding perceptual domains and employing a layer-by-layer aggregation mechanism for the integration of different levels of features. Chen et al. [21] performed entity recognition of electronic medical records based on IDCNN and CRF, and with the introduction of an attention mechanism to highlight the importance of different locations, the recognition accuracy and model training speed were higher than those of BiLSTM. Hu et al. [22] designed a 4-layer dilated convolutional neural network (DCNN) to convolve the vector output from the attention layer, which can expand to all the data in the input matrix after only 3 steps of expanding the expansion of the sensory domain, and the same number of parameters in each layer can effectively reduce the parameters during the training, and the results show that it can speed up the training speed while taking into account the accuracy. Zhao et al. [23] proposed duplex CNN by combining IDCNN with CNN, which can make full use of GPU’s parallel capability and ensure the integrity of local contextual information under the premise of extracting long-distance semantic information, and achieved better results on Microsoft research Asia named entity recognition (MSRA) and Resume datasets. The aforementioned proposed structures have brought new perspectives to CNER.
Despite the advancements in the model structures discussed above, several challenges in current CNER remain inadequately addressed. One prominent issue, illustrated in Fig. 1, is the difficulty in accurately identifying nested entities such as “北京” (Beijing), “鸭” (duck), and “北京烤鸭” (Peking duck). This challenge is particularly prevalent in domain-specific texts, including those in the medical and paleontological fields.
![]()
Figure 1.An example of nested entities.
To address this issue, we propose a multi-scale IDCNN method. Building upon word segmentation, this network effectively disentangles nested entities. In extracting lexical feature information, the network employs dilation at various scales to capture the local features of each nested entity. However, focusing solely on the local features of each entity is insufficient to improve recognition accuracy. To enhance performance, we integrate another commonly used network structure that considers global features. This combination of approaches significantly enhances the resolution and accuracy of nested entity recognition.
In addition, the proposed structure effectively addresses a common issue in CNER tasks, as illustrated in Fig. 2. In the first sentence, “苹果” (apple) represents the brand Apple, while in the second sentence, “苹果” (apple) represents the fruit. This exemplifies entity ambiguity. Although pre-trained models like BERT can dynamically generate word vectors based on the context to tackle polysemy, they may struggle to distinguish between different entity categories in scenarios where contextual differences are not explicitly clear.
![]()
Figure 2.An example of an ambiguous entity word.
To overcome this limitation, our proposed model builds upon BERT and introduces a word embedding model based on skip-gram with negative sampling (SGNS) pre-training. The segmented lexical information is processed using enhanced IDCNN. This model integrates contextual hints into traditional character representations, thereby improving the resolution of entity ambiguity issues in the cases of high similarity.
Our proposed method represents an innovative approach that integrates both character and lexical information. It incorporates the multi-scale iterative dilated convolution for the feature extraction of lexical embedding information. Additionally, it incorporates an inter-word multi-attention strategy, ensuring the preservation of character context information while extending the scope of lexical information. The key contributions of our approach can be summarized as follows:
1) We introduce a sophisticated deep neural network model featuring a diverse set of networks for word feature extraction in the feature extraction layer. This approach employs a multi-scale strategy to effectively extract lexical information. Additionally, a multi-head attention mechanism is utilized for seamless fusion and integration of features.
2) Our model architecture exhibits flexibility by enabling the straightforward adjustment of the number of iterative blocks in the dilated convolution, various scales, and the expansion rate for participle feature extraction. This adaptability facilitates achieving optimal model performance based on specific requirements.
3) A series of experimental results show that the proposed model outperforms mainstream CNER models, and the results of the ablation experiments verify that our approach can effectively incorporate the lexical information.
2 Related work
This section introduces the research closely related to our proposed model, primarily focusing on using pre-trained models for CNER tasks and incorporating multiple features to enhance the model performance in CNER.
2.1 CNER based on pre-trained models
In recent years, pre-trained models have been widely applied in entity recognition. These models are typically trained on large-scale datasets, possessing general understanding of language patterns, and can be fine-tuned for specific tasks to enhance the accuracy and efficiency of recognizing named entities in various contexts. For example, the emergence of BERT [24] and Generative Pre-trained Transformer (GPT) [25] has further improved the performance of NER, which pre-learns linguistic representations on the large-scale text and then fine-tunes them on NER tasks. Dai et al. [26] in the medical domain effectively extracted valuable medical information from electronic health records by comparing multiple NER neural networks, including BiLSTM, and utilizing a BERT pre-trained model in conjunction with BiLSTM and CRF. Yu et al. [27] recognized the challenges posed by diverse entity types, semantic complexity, and a large number of rare characters in the Chinese mineral text, and achieved notable accuracy in mineral named entity recognition (MNER) using BERT-CRF. Addressing the issue of low performance in CNER tasks with large language models, Wang et al. [28] proposed GPT-NER, incorporating a self-validation strategy. The results indicate that GPT-NER demonstrates enhanced capabilities, particularly in low-resource and few-shot scenarios.
All these studies have explored CNER based on the current mainstream pre-trained models. However, due to the complexity of the Chinese language, they did not consider additional feature fusion to enhance the accuracy of CNER.
2.2 CNER with multi-feature fusion
Based on pre-trained models, multi-feature fusion is also gaining attention in entity recognition tasks, which leads to a rich information representation and improves the generalization of the model across different datasets, and, more importantly, improves the accuracy of recognition. Yan et al. [29] proposed an improved dual-channel network, which utilizes the bidirectional gated recurrent unit (BiGRU) to extract sequence-wide contextual information features and employs enhanced DGCNN with residual connections, a gated dilated convolutional network, to extract local sequence features for representing lexical information features. These features were combined using a sparse attention mechanism. The experimental results demonstrate the model’s effectiveness in enhancing entity recognition capabilities. Yang et al. [30] proposed the attentive multilevel feature fusion (AMFF) model, which integrates semantic and syntactic information from a multi-level perspective. This model captures multi-level features from different angles in the current context. To enhance the representation learning for the current context, it also defines document-level features extracted from other sentences. Building upon the AMFF model, the context-aware attentive multilevel feature fusion (CAMFF) model is introduced to make full use of all previously input document-level features. The obtained multi-level features are then fused and input into a BiLSTM and CRF network for the final sequence labeling. The results indicate that the AMFF and CAMFF models outperform a set of state-of-the-art baseline methods, and the features learned from multiple levels are complementary. Deng et al. [10] proposed a method to enhance the performance of CNER by augmenting semantic information. This approach extracts various types of syntactic data, employs a key-value memory network (KVMN) to operationalize syntactic information, and merges it using an attention mechanism. Subsequently, it integrates syntactic and lexical information to obtain semantic information through a cross-transformer. Finally, an internal rule-aware module is used to capture internal rules for each entity and combine them with the semantic information for entity recognition. Experimental results demonstrate that this model effectively improves the performance of CNER. Tian et al. [11] proposed a multi-task learning method mainly used for assisted word selection in dictionary-enhanced CNER. The multi-tasks were expressed as scoring the matched words to select some of the most useful words and integrating the selected words through multiple heads of attention, so as to improve the quality of vocabulary as well as the match between vocabulary and the corpus in order to enhance the effect of CNER. Long et al. [31] proposed a multi-embedding fusion method. This method primarily uses the convolution to combine the contextual information of the sequence in order to obtain various features for each character. These features include word features, contextual features, double-word features, and double-word contextual features. This method also fuses the information at the embedding layer using these four different features, employs a self-attention mechanism to integrate lexical information, and generates four different word embeddings through cascading. Finally, it inputs the fused feature information into the coding and decoding layers. The experimental results on three datasets show that the model can effectively improve the performance of CNER.
The aforementioned work indicates that multi-feature fusion has become a crucial research area in CNER. In the context of multi-feature fusion, effectively incorporating lexical information has a positive feedback effect on model classification accuracy. Currently, several methods have fused lexical information with character features to provide more comprehensive character-level feature representations. Wang et al. [32] proposed an interactive fusion method that integrates character and lexical information. Initially, they incorporated character and lexical features in a graph neural network, followed by further enhancement of the fusion through a feedforward neural network and residual connections to achieve secondary fusion, resulting in a more comprehensive feature representation. Their experiments on multiple datasets demonstrate that lexical information significantly impacts the entity recognition accuracy. Li et al. [33] proposed an improved CNER model, which integrates pinyin and part-of-speech information with character embeddings. By incorporating related lexical information, they enhanced the semantic representation of the text, thereby achieving more effective NER, which was then applied in clinical knowledge graphs and intelligent question-answering systems. Qiu et al. [34] combined geological BERT (GeoBERT) embeddings with various lexical features, such as position and radicals, to generate representations from character sequences. This approach improves the accuracy of NER for geological knowledge and demonstrates that lexical information is beneficial for entity recognition in publicly available datasets. Liu et al. [15] incorporated domain-specific lexical features and introduced an automatic updating mechanism for a custom dictionary. They proposed a method capable of adaptively capturing and recognizing newly emerging entities to be added to the custom dictionary. The iterative interaction between the two methods enhanced the recognition accuracy and minimized the reliance on manual intervention.
From the above methods, we can conclude that lexical information positively influences the accuracy of NER. In various domains, such as geology and medicine, incorporating lexical information enhances the accuracy of NER. Features like part-of-speech, radicals, components, and word boundaries contribute to a richer contextual representation of the text, leading to more comprehensive feature representations and improved training. This paper proposes the BERT character word CRF (BCWC) model, which focuses on using the semantics of words as lexical information. It distinguishes word boundaries through the semantic integrity of the words, ensuring semantic completeness during word filtering. This approach eliminates the need for highly accurate part-of-speech taggers, as seen in Ref. [33], which relied on part-of-speech information. It also reduces the manual effort required for part-of-speech annotation, especially when the tagging accuracy is low. Moreover, it addresses the limitations of Ref. [34], which integrated radical features but restricted the method to words with distinct radical structures. In the BCWC model, RNNs are used to capture global dependencies and CNNs are applied to extract local features. Unlike conventional CNNs used in image recognition, we apply the one-dimensional convolution to word-embedding vectors. Since words already contain boundary information, this enhances the correlation between words, making it more effective for handling compound words. The multi-scale dilated iterative convolution in BCWC has unique characteristics. Its iterative dilated convolution extracts deeper features, improving precision in feature fusion. Different dilation rates create varied receptive fields, minimizing the information loss during pooling and preserving more complete input information. This ensures richer and more precise representations of embedding vectors. The use of convolutional kernels with different scales allows for a wider range of combinations during segmentation, further optimizing word boundary information. In the feature fusion layer, we avoided the two-stage fusion method proposed by Wang et al. [32] , which risks propagating and amplifying errors. After comparing feedforward neural networks and multi-head attention mechanisms as fusion strategies, the multi-head attention mechanism was chosen. This approach effectively resolves mismatches between character and word sequences during fusion and captures their interrelationships. By normalizing attention weights, it reflects the importance of character and word features in different contexts, thereby enhancing classification accuracy in downstream tasks.
3 Methods
Our proposed BCWC model is illustrated in Fig. 3. The model is structured with a multi-network architecture, leveraging BERT for the word embedding representation of input data. Additionally, a pre-trained word embedding model based on the SGNS approach is employed for the word embedding representation of segmented word data. The word embeddings are further processed using a BiLSTM network for feature extraction, enhancing the contextual information. The iterative dilated convolution is applied at multiple scales to capture features at varying resolution. At the feature fusion layer, various fusion strategies are compared, and a multi-head attention mechanism is employed to amalgamate word information, producing the final representation. The decoding layer incorporates CRF for optimal sequence annotation. To validate the superior accuracy and performance of our proposed model compared with other state-of-the-art models, comprehensive tests are conducted on diverse datasets, including CLUENER [35], Weibo [36], and Youku [37].
![]()
Figure 3.Comprehensive architecture of the BCWC model, consisting of four main layers: Embedding layer, feature extraction layer, feature fusion layer, and CRF layer. The embedding layer incorporates BERT and word embedding models for character and word embeddings, respectively. In the feature extraction layer, varied colored dashed boxes represent the range of word sequences captured by convolutional kernels of different scale sizes. The outcomes of these convolutions are seamlessly concatenated to form the final output. Subsequently, the feature fusion layer employs a multi-head attention mechanism for word weighting, culminating in the transmission of the output to the CRF layer for decoding. This layered structure ensures a comprehensive and efficient approach to information processing in the BCWC model.
3.1 Embedding layer
3.1.1 BERT
To comprehensively capture the semantic information of the text, character data is embedded using the BERT pre-trained model for embedding representation. BERT acquires context-dependent embeddings primarily through two pre-training tasks: Masked language modeling (MLM) and next sentence prediction (NSP). In the MLM task, certain words in the input sentences are randomly masked, and the model is trained to predict these masked words. The NSP task involves presenting the model with a pair of sentences and tasking it by predicting whether these sentences are adjacent in the original text. The resulted embeddings, token embeddings, segment embeddings, and position embeddings, synthesize contextual information in the text, accounting for the entirety of the text sequence. This approach ensures more comprehensive understanding of semantic nuances within the input data. For a piece of text data
3.1.2 Word2Vec (SGNS)
To enhance the introduction of lexical information, we employ an established Chinese lexical database for data segmentation. During the segmentation process, we take additional measures to improve the quality of segmentation. This involves meticulous filtering and screening of words to eliminate stop words and characters other than Chinese characters, numbers, and English letters. Subsequently, we select an appropriate word embedding pre-training model to accurately represent the vocabulary in embeddings. This careful approach ensures the incorporation of high-quality lexical information into the model, contributing to improved overall performance.
Li et al. [38] introduced a Chinese analogical reasoning task and developed a substantial and balanced dataset called CA8 to serve as a benchmark for evaluating Chinese word embeddings. In our work, we draw inspiration from their research to choose an appropriate word embedding model for our word segmentation data. Specifically, we opt for SGNS among pre-trained models based on both SGNS and positive pointwise mutual information (PPMI). SGNS, a common method for learning dense word vectors, outperforms PPMI in analogical reasoning of morphological relations. The SGNS-based word embedding model excels in capturing semantic information in lexical contexts and provides richer contextual information for the entity recognition task by learning co-occurrence relations among words during pre-training. Specifically, SGNS consists of the skip-gram model and negative sampling, the skip-gram model was first proposed by Mikolov et al. [39]. It is designed to process the large-scale textual data to obtain distributed representations of words, which consists of two core models of Word2Vec, the skip-gram model and the continuous bag-of-words (CBOW) model. The optimized version of these models is negative sampling, proposed by Mikolov et al. [39]. In the proposed skip-gram model, Mikolov et al. [39] stated that the goal of the model is to maximize the conditional probability of a context word appearing within a context window given a target word. Specifically, for a given central word wt and a context word wc within a context window, we wish to maximize the following conditional probability, given as
where
In the original skip-gram model, the training process needs to consider all possible contextual word pairs, which leads to an increase in computational complexity, especially when the vocabulary list is large. In order to speed up the training and reduce the computational cost, and considering that the skip-gram model only focuses on learning high-quality vector representations, Mikolov et al. [39] proposed the idea of negative sampling compared to noise contrast estimation (NCE). For each training sample (wt, wc), the traditional training goal is to maximize the conditional probability of correct context words, but negative sampling changes this goal to minimize the conditional probability of negative example context words, where the negative examples are K randomly selected words from the vocabulary that have not appeared in the context, denoted as
A detailed derivation of the embedding method can refer to Ref. [40]. The optimization objective of SGNS is to maximize the conditional probability of the correct contextual vocabulary while minimizing the conditional probability of the negative example contextual vocabulary. Therefore, the optimization objective of SGNS can be expressed as maximizing the likelihood function as follows:
where R denotes positive case context word pairs and N denotes negative case context word pairs. The SGNS model is trained by using optimization algorithms such as gradient descent to adjust the values of the word embedding vectors. The model is constantly updated to increase the conditional probability of the positive case context words and to decrease the conditional probability of the negative case context words so that word embedding vectors are learnt for each word. This approach makes the training more efficient.
3.2 Feature extraction layer
3.2.1 BiLSTM
In the realm of deep learning, RNNs stand out as crucial tools for processing sequence data. Traditional RNNs, however, often struggle to capture long-distance dependencies due to issues like vanishing gradients. LSTM, a specialized type of RNN, addresses this limitation by incorporating a gating mechanism. This mechanism effectively preserves time-step features, enabling the model to capture contextual relationships within sequences more effectively. Building on the advancements of unidirectional LSTM, BiLSTM further optimizes sequence processing. BiLSTM employs two directional LSTM units to process sequences from both front to back and back to front. This bidirectional approach ensures that each time step in the sequence considers information from both preceding and succeeding elements. Consequently, BiLSTM enhances the network’s ability to capture intricate dependencies across the entire sequence, significantly improving the performance in tasks that require comprehensive contextual understanding.
The model we present integrates multiple networks to fuse character and word embeddings. For character feature extraction, we utilize BiLSTM, which takes the output from BERT character embeddings as input. This network incorporates internal gating mechanisms, including input gates, forget gates, and output gates, which regulate the flow of information and memory updates. Coupled with the bidirectional mechanism, these gates facilitate the capture of long-distance dependencies, thereby enhancing the model’s ability to effectively handle lengthy sequences. This augmentation contributes to a richer semantic context in conjunction with BERT character embeddings. The specific formulas for the LSTM gates are defined as follows:
where
The aforementioned methods are used to perform forward and backward feature extraction on the text. Two independent and parallel LSTM networks are employed to process the sequence: One proceeds from left to right, denoted as
3.2.2 Multi-scale IDCNN
CNNs leverage convolutional kernels to detect local features at various locations within input data. Originally designed for image feature extraction, CNNs have seen expanded use in NLP as research in this field has progressed. Increasingly, researchers are incorporating CNN into CNER tasks due to their ability to capture intricate patterns and hierarchical features within textual data. This adoption underscores the adaptability and effectiveness of CNN in the evolving landscape of NLP tasks.
This paper extends the concept of iterative dilated convolution by introducing a multi-scale iterative dilated convolution to extract features from segmented token information at different scales. Given that entity recognition tasks involve processing text sequences, the one-dimensional convolution is commonly utilized for convolution operations. It adeptly manages text sequences of diverse lengths and autonomously learns local features within the text.
Our approach involves constructing two structurally identical dilated CNN modules concatenated together. Each module comprises two regular convolution layers and one dilated convolution layer. To enhance feature extraction, we replicate this structure to construct another dilated CNN module, utilizing distinct convolution kernel sizes and varied dilation rates to capture features at different scales. Additionally, ReLU activation functions are consistently applied to introduce non-linearity, while layer normalization is employed to address concerns related to gradient vanishing and exploding.
The embedding layer uses the pre-trained word embedding model to represent the embedding of the participle, noting that the word embedding result is denoted as
The word embedding sequence undergoes a convolution operation using the regular convolution, resulting in a feature sequence. The dilated convolution is applied to this feature sequence with a dilation rate denoted as d. Different dilated CNN modules have varying dilation rates. Due to the presence of holes in the dilated convolution, its receptive field is larger than that of the regular convolution, enabling it to capture longer subsequences.
where
For the convolution results
where m represents the number of convolution kernels,
The multi-scale IDCNN structure, as illustrated in Fig. 4, represents a novel design that provides notable advantages in entity recognition tasks, particularly in the context of lexical information. In this study, word embeddings are derived from segmented data, resulting in static word embeddings that do not dynamically change on their own. To comprehensively augment the lexical information, we employ the convolution with different kernel sizes to address various word sequence lengths. Furthermore, the convolution with distinct dilation rates enables the capture of dependencies at varying distances, thereby enriching lexical information and enhancing the model’s adaptability. This innovative design ensures a more robust approach to extracting nuanced features from segmented token data in entity recognition tasks.
![]()
Figure 4.Multi-scale IDCNN process diagram. The input consists of word embedding vectors. The diagram showcases two different scale iterative dilated convolution blocks. When , a regular convolution kernel is used, and when , the dilated convolution is employed. Each convolution block comprises two stacked layers. The results are concatenated and activated using the ReLU function, followed by normalization with LayerNorm. The outputs from different scales are concatenated to obtain the final output.
3.3 Feature fusion layer
In this study, we employed two distinct feature fusion approaches: Fully connected layer and multi-head attention mechanism. We experimented with these fusion mechanisms across diverse datasets, including CLUENER [35], Weibo [36], and Youku [37].
3.3.1 Fully connected layer
When integrating character-level features and word-level features, discrepancies in the lengths of character sequences and word sequences can give rise to issues such as dimension mismatch or alignment problems. While a prevalent approach to mitigating this problem involves using padding and truncation to equalize the lengths, we opt for an alternative strategy to avoid information redundancy and loss. Specifically, we utilize a fully connected layer to harmonize the sequence dimensions after concatenating the character and word embeddings. This process ensures a seamless integration of character and word features while maintaining the integrity of information without unnecessary padding or truncation. The specific steps in this process are outlined as follows:
where
3.3.2 Multi-head attention layer
In the CNER task, the attention mechanism proves effective in capturing crucial information from various locations in the text. This capability enhances contextual understanding, and the multilingual performance of the attention mechanism allows it to adapt to diverse contextual characteristics and structures. In our approach, we leverage the multi-head attention mechanism for word fusion, offering two primary advantages in this task.
First, it facilitates the dynamic weighting of words, allowing the model to assign varying importance to different words based on the context. Second, it addresses the challenge of length mismatch between character sequences and word sequences. The specific formula for implementing this multi-head attention mechanism is as follows:
where embedding_dim represents the word embedding dimension, head denotes the number of attention heads in the multi-head attention mechanism, dk represents the embedding dimension assigned to each head,
![]()
Figure 5.
Overall, the attention mechanism allows the model to assign different weights to each character and its corresponding word within a sample. This dynamic adjustment enables the model to adaptively focus on the most relevant characters for the current task based on contextual changes. As a result, it reduces interference from noisy data and minimizes errors caused by ambiguity, thereby enhancing the accuracy of NER. By computing multiple attention heads in parallel, the model captures character-word relationships from various perspectives, facilitating comprehensive understanding of the context. This improves the model’s ability to parse complex semantics, giving it a competitive edge in NER tasks.
3.4 CRF layer
In order to fully consider the sequence information as well as the dependency relationship between the labels, we use the standard CRF to process the results after the fusion layer to obtain the optimal sequence annotation, noting that the final label sequence
where
3.5 Case study
In this subsection, we illustrate the design of the BCWC model through a case study, including how this design incorporates lexical information and employs various neural network structures for feature extraction to obtain more comprehensive contextual understanding, and we demonstrate the importance of learning this information.
Taking the sample sentence “地处北京的中国科学院于2023年与武汉小米科技公司在深圳签署了一项关于云计算的合作协议” (The Chinese Academy of Sciences, located in Beijing, signed a cooperation agreement on cloud computing with Xiaomi Technology Company in Wuhan in 2023) as an example, this sentence contains multiple important named entities, such as organization names of 中国科学院 (Chinese Academy of Sciences) and 小米科技公司 (Xiaomi Technology Company), locations of 北京 (Beijing), 武汉 (Wuhan), and 深圳 (Shenzhen), and the topic of 云计算 (cloud computing). These entities vary in length and complexity, posing higher demands on the model’s recognition accuracy. The correct named entities should be identified as Fig. 6 shows.
![]()
Figure 6.Correctly identified named entities of the sample.
In the BCWC model, the original text will be processed through two different channels: RNN and CNN. In the RNN module, BiLSTM can capture most of the long-range dependency information in the sentence.
For example, it can effectively identify the relationship between “中国科学院” (Chinese Academy of Sciences) and “2023年”, enhancing the understanding of the temporal and locational semantic relationships between the two. However, without “2023年”, the entity “中国科学院” (Chinese Academy of Sciences) may be challenging to being correctly recognized within a BiLSTM framework. Additionally, BiLSTM helps connect the subsequent term “云计算” (cloud computing) with the previously mentioned organization name, improving the overall comprehension of the text’s semantic structure. This demonstrates that BiLSTM can accommodate global contextual information. However, in certain cases involving compound terms, such as “小米科技公司” (Xiaomi Technology Company) and “中国科学院” (Chinese Academy of Sciences), relying solely on BiLSTM often fails to effectively identify named entities. For instance, “小米科技公司” (Xiaomi Technology Company) might be misclassified as “小米” (Xiaomi), a type of food entity, while “中国科学院” (Chinese Academy of Sciences) could lead to “中国” (China) being identified as a location entity and “科学院” (Academy) as an organization entity. This indicates that while BiLSTM captures some contextual information, it tends to lose the local context when dealing with long-range dependencies, especially in the rapidly evolving field of information technology. Many Chinese words have multiple meanings, particularly ambiguous terms like “小米” (Xiaomi) and “苹果” (Apple), which are prone to misclassification.
The BCWC model employs IDCNN to address this issue. After considering various lexical information such as part-of-speech and radicals, the semantic information of the words themselves is used as features. The segmented data from the example is obtained after filtering the tokenized input, as shown in Fig. 7. The segmented data can shorten the text length, with each word having its corresponding semantic word embedding. This processing ensures that the judgment between characters in composite terms is transformed into a judgment between words. In simple terms, this approach enhances the boundary capability and reduces misidentification during the recognition process, leading to better accuracy in NER. As shown in Fig. 8, assuming the same-sized context window, when “小米科技公司” (Xiaomi Technology Company) is treated with each character as a token, the loss of local information can lead to the entity being incorrectly recognized as a food entity from the very beginning. In contrast, treating each word as a token ensures that the inherent boundary information and the semantic relationships between words help guarantee the correct identification of the entity.
![]()
Figure 7.Tokenization and multi-scale convolution kernel capturing process.
![]()
Figure 8.Entity recognition under the same information capture window size.
In addition, the BCWC model employs a multi-scale dilated convolution structure to process lexical information. A significant advantage of the dilated convolution is its ability to capture long-range dependency information by expanding the receptive field. For example, between the two long organization names “中国科学院” (Chinese Academy of Sciences) and “小米科技公司” (Xiaomi Technology Company), there are multiple intervening terms like “2023年” and “武汉” (Wuhan). However, the dilated convolution can simultaneously focus on these long named entities at the sentence level through a larger receptive field, capturing their complete information, which is particularly beneficial for tokenization of long entities. The multi-scale convolution structure allows the convolution kernels to cover different receptive fields, capturing lexical contextual features across varying ranges, making it suitable for situations where local relationships between words are strong. For example, in the entity “小米科技公司” (Xiaomi Technology Company), the terms “小米” (Xiaomi), “科技” (Technology), and “公司” (Company) typically have a tight contextual correlation, representing local features of this type of the named entity. The multi-scale receptive fields of IDCNN can effectively capture the overall semantics of this phrase, avoiding loss of entity information due to limitations in the local window size, thus efficiently extracting these local features. This prevents the misclassification of “Xiaomi” as an incorrect entity category. The multi-scale capture results are shown in Fig. 7.
Finally, the BCWC model employs a multi-head attention mechanism for feature fusion at the feature fusion layer, utilizing the relationships between characters and words. In traditional models, the segmented characters are often treated equally, without the flexibility to adjust based on their importance within the words. However, this multi-head attention mechanism introduces dynamic weight adjustments, allowing the model to more accurately determine which characters contribute more significantly to NER of the entire word. This is particularly beneficial when the lengths of the character and word sequences are inconsistent. On one hand, it can standardize the lengths of the character and word sequences; on the other hand, the weight matrix helps the model understand which characters and words are the most important for the current NER task.
4 Experiments
4.1 Experimental settings
4.1.1 Datasets
Our model is evaluated on three Chinese datasets, including CLUENER [35], Weibo [36], and Youku [37], where CLUENER is a Chinese fine-grained named entity recognition dataset containing news and social media texts, which covers a wide range of domains, Weibo is a dataset on Sina Weibo from the social media domain, and Youku is from the entertainment domain. All datasets are divided into training data, evaluation data, and test data. The total number of sentences, categories, and characters in each dataset is shown in Table 1.
| Hyperparameter | Value |
| RNN dimension | 64 |
| BERT learning rate | 2×10–5 |
| BERT dropout rate | 0.35 |
| RNN(CNN) learning rate | 1×10–3 |
| Kernel size | 3 |
| Boundary embedding dimension | 16 |
| BERT model | BERT-base-Chinese |
| Epoch | 30 |
| Optimizer | AdamW |
| Multi-head attention head | 8 |
Table 1. Some common hyperparameter settings about the experiments.
Additionally, the reason we chose these three types of public datasets is to comprehensively evaluate the BCWC model. CLUENER is a dataset specifically designed for NER tasks, focusing on recognizing different types of entities such as names of people, places, organizations, addresses, companies, products, and events. Its data comes from a wide range of sources and covers multiple real-world application scenarios, with a high level of complexity. It typically requires contextual understanding to determine the entity type, making it suitable for testing the BCWC model’s accuracy in recognizing compound words and complex entities across various contexts. The Weibo dataset contains informal language, colloquial expressions, and a significant amount of noisy data. As it belongs to the entertainment domain, which closely follows current trends, this dataset includes many ambiguous or newly coined Internet words. It is ideal for testing the BCWC model’s performance in informal language environments and for validating the multi-scale iterative dilated convolution’s ability to extract contextual information from words. The Youku dataset contains diverse text structures, including formal descriptive texts such as introductions to film and television works, plot summaries, and cast lists, as well as informal commentary texts, such as user comments posted on video websites, which often include Internet slang, popular phrases, or even pinyin abbreviations and symbols. The film and TV descriptions or reviews often involve long text paragraphs, which can test whether dilated convolutions, by expanding the receptive field, and can capture broader contextual information, which is crucial for recognizing complex entities in long texts. Furthermore, the formal descriptive texts often involve complex entities like film titles or character names, where there is a strong dependency between characters. This allows us to validate the multi-head attention mechanism introduced in the BCWC model, which establishes weighted relationships between words and characters, helping the model capture both intra-entity and inter-entity relationships. This, in turn, improves the representation of semantic relationships between words and enhances the recognition accuracy of complex entities in film and television works.
4.1.2 Baselines
To assess the effectiveness of our multi-network fusion approach for incorporating lexical information, we conducted a comparative analysis with several established methods. Given that we utilized both RNNs and CNNs for the downstream task, our selection included models representing the latest advancements in both RNN-based NER and CNN-based NER. Additionally, we incorporated lexicon-augmented NER models in our comparison. This comprehensive selection ensures thorough evaluation against existing state-of-the-art methods across various approaches in the field of NER. The chosen models are as follows:
1) Methods that do not incorporate lexical information using RNN: BiLSTM-CRF, BERT-CRF, RoBERTa-WWM-BiLSTM-CRF [41], and ALBERT-BiLSTM [42]. The BiLSTM-CRF model embeds characters into a BiLSTM network and utilizes CRF for decoding. The BERT-CRF model, built on top of the pre-trained BERT model for embeddings, adds an additional CRF layer. The RoBERTa-WWM-BiLSTM-CRF model leverages the RoBERTa pre-trained model for embeddings, introduces BiLSTM to enhance contextual information, and ultimately employs CRF. The ALBERT-BiLSTM model adds an extra BiLSTM layer on top of the pre-trained ALBERT model.
2) Methods that do not incorporate lexical information using CNN: Text convolutional neural network-conditional random field (TextCNN-CRF) [43] and fusion glyph network (FGN) [44]. The TextCNN-CRF model combines the features of pinyin and characters using TextCNN for feature fusion and employs CRF for optimal sequence labeling. FGN introduces a novel CNN structure, namely character graph sequence convolutional neural network (CGS-CNN), to capture character shape information and interaction information between adjacent graphs.
3) Methods that utilize RNN and incorporate lexical information: Lattice long short-term memory (Lattic-LSTM) [45] and stacked bidirectional gated recurrent unit-conditional random field (stkBiGRU-CRF) [46]. Lattic-LSTM leverages gated recurrent units to utilize lexical information within the character sequence. stkBiGRU-CRF embeds characters into stacked BiGRUs and utilizes a CRF layer to decode the predicted entity outputs.
4) Methods that utilize CNN and incorporate lexical information: Lexicon rethinking convolutional neural network (LR-CNN) [47] and lexicon-based graph neural network (LGN) [48]. LR-CNN introduces the concept of modeling latent relationships to better understand relationships between entities, encoding potential words of different window sizes using CNN. LGN connects relevant characters based on the lexicon word, allowing CNN to capture local structural information and transforming NER into a node classification task within a graph.
5) Finally, we also introduced some of the latest research from the past two years that integrates lexical information as well as studies that do not incorporate lexical information, and conducted a comparative analysis with the BCWC model: Multi-task learning with helpful word selection (MTL-HWS) [11], BiLSTM+SSCNN-CRF [49], KCB‑FLAT [50], label knowledge and lexicon information (LkLi-CNER) [51], and deep span encoder representations from transformers (DSpERT) [52]. The MTL-HWS (BERT-base) model employs multi-task learning to assist in word selection for enhancing CNER with a dictionary. BiLSTM+SSCNN-CRF combines dictionary matching for word information, utilizing SSCNN and BiLSTM to capture both local and global hidden details of the sequences, and finally employs a CRF layer to handle sequence hidden states. KCB-FLAT combines rich semantic information with word boundary smoothing techniques to improve the performance of CNER. LkLi-CNER introduces relevant prior knowledge by matching vocabulary with sentences, and then integrates label semantic information into enhanced text representations, enhancing the model through the semantics of the labels themselves. The DSpERT model uses a standard transformer and a span transformer to achieve a deep semantic span representation to complete the task of NER, but the model does not use lexical information.
4.1.3 Evaluation metrics
We evaluate the models in this paper using most of the baselines, including precision, recall, and F1-score.
Precision is how many of the entities identified by the model are true entities. By noting the number of entities correctly identified by the model as
Recall is used to measure the ability of the model to successfully identify all the target entities that are actually present. By noting
F1-score is an evaluation metric that combines recall and precision to measure the performance of the model, and is calculated by combining both recall and precision metrics in order to evaluate the model performance more comprehensively in different situations, which is calculated by
Overall, precision indicates how many of the entities predicted by the model are actual entities. A high precision value means that the model rarely misidentifies non-entities as entities. Recall indicates how many of the actual entities are correctly recognized by the model. A high recall value means the model has a strong ability to recognize entities but may result in more false positives. F1-score balances precision and recall. If a model has high precision but low recall, or vice versa, F1-score provides a comprehensive evaluation. An F1-score value close to 1 indicates that the model has a good balance between precision and recall. In a case study, the model correctly identified “小米科技公司” (Xiaomi Technology Company) as an entity without any false positives in other parts of the text. In this case, TP is 1, FP is 0, and FN is 0, resulting in both precision and recall being 1, and F1-score of 1. However, if the model incorrectly identified “北京” (Beijing) as an organization, when it is actually a place, FP would increase to 1, causing a decrease in precision.
4.2 Experimental results
Tables 2, 3, and 4 present the experimental results of different models on the CLUENER, Weibo, and Youku datasets. The evaluation metrics include precision, recall, and F1-score. Precision and recall influence each other; typically, improving precision can affect recall, and conversely, pursuing high recall often lowers precision. Therefore, in NLP tasks, F1-score is commonly used as the primary evaluation metric. This paper adheres to this principle, considering the performance of different models based on F1-score to provide a comprehensive comparative analysis.
| Dataset | max_seq_len | Batch size | max_word_len |
| CLUENER | 128 | 32 | 25 |
| 64 | 16 | 20 | |
| Youku | 128 | 16 | 20 |
Table 2. Some hyperparameter settings about the experiments on the three datasets.
| Model | Precision (%) | Recall (%) | F1-score (%) |
| BiLSTM-CRF (2020) | 60.80 | 52.90 | 56.58 [ |
| Lattice-LSTM (2018) | 53.04 | 62.25 | 58.79 |
| LR-CNN (2019) | 57.14 | 66.67 | 59.92 |
| LGN (2019) | 56.44 | 64.52 | 60.21 |
| BERT-CRF (2019) | 67.12 | 66.88 | 67.00 [ |
| FGN (2021) | 69.02 | 73.65 | 71.25 |
| MTL-HWS (2023) | 73.03 | 73.21 | 73.12 |
| DSpERT (2023) | 69.52 | 68.80 | 69.12 |
| KCB-FLAT (2024) | 72.36 | 70.41 | 71.37 |
| LkLi-CNER (2023) | 77.43 | 68.23 | 72.54 |
| Ours | 71.96 | 75.32 | 73.60 |
Table 3. Performance on Weibo.
| Model | Precision (%) | Recall (%) | F1-score (%) |
| BiLSTM-CRF (2020) | 80.31 | 79.22 | 79.76 |
| BERT (2018) | 85.06 | 76.75 | 80.69 |
| BERT-CRF (2019) | 83.00 | 81.70 | 82.40 [ |
| Lattice-LSTM (2018) | 84.43 | 81.28 | 82.82 |
| BiLSTM+SSCNN-CRF (2023) | 87.00 | 85.10 | 86.10 |
| DSpERT (2023) | 86.62 | 80.17 | 83.27 |
| Ours | 87.41 | 86.97 | 87.19 |
Table 4. Performance on Youku.
The BCWC model demonstrates improvements over other models, achieving higher precision, recall, and F1-score on the Youku dataset, as shown in Table 4. On the CLUENER dataset, the BCWC model also attained higher precision and F1-score, as indicated in Table 2. Although recall of the BCWC model is slightly lower than that of the ALBERT-BiLSTM model, the difference is not significant. This may be attributed to the BCWC model’s multi-network architecture, which extracts and integrates various features. However, this complexity can lead to challenges, such as increased difficulty in optimizing the model during training, which may hinder its performance on specific tasks, particularly impacting recall. In contrast, ALBERT-BiLSTM features a simpler structure, making it easier to optimize and resulting in more stable recall performance. On the Weibo dataset, as shown in Table 3, the BCWC model achieved higher F1-score, but its precision and recall values exhibit a complementary relationship compared with the LkLi-CNER model. This may be due to LkLi-CNER’s integration of label semantic information into enhanced text representations, improving the accuracy and reducing false positives. While this approach may lead to some missed entities (resulting in slightly lower recall), it produces more reliable outputs, thus excelling in precision. Conversely, the BCWC model employs a multi-scale strategy that captures features at different scales, allowing it to identify more potential entities. This means it may recognize more entities but at the cost of lower precision. Specifically, the BCWC model achieved F1-score of 79.86% on the CLUENER dataset, 73.60% on the Weibo dataset, and 87.19% on the Youku dataset.
Among these models, BiLSTM-CRF, stkBiGRU-CRF, and TextCNN-CRF do not utilize pre-trained language models. While these traditional models excel in sequence modeling and local feature extraction, their lack of large-scale pre-training hinders their ability to capture rich contextual semantics, as seen with BERT and ALBERT. Consequently, they exhibit weaker generalization capabilities on complex tasks, resulting in lower F1-score across the three datasets. This reinforces our earlier assertion in Section 1 that current CNER methods tend to favor combinations of pre-trained models and downstream neural networks. The lattice-LSTM model also operates without pre-trained models but achieves higher F1-score than the aforementioned models. This is because lattice-LSTM is an early network structure designed to integrate lexical information, effectively combining traditional sequence models with lexical data. Thus, it illustrates that incorporating lexical information can significantly enhance the accuracy of NER, even in traditional networks that do not commonly employ pre-trained models. In the CLUENER dataset, BERT achieves a higher F1-score value than ALBERT. This difference arises because ALBERT reduces the model size through parameter sharing and factorized embeddings, which can lead to some information loss and affect its learning capacity. While BERT delivers strong performance, it requires a larger number of parameters, resulting in higher resource consumption during training and inference. In contrast, ALBERT is more efficient. The BCWC model, built on BERT, naturally outperforms the other models, and this trend is consistent across the other two datasets. The RoBERTa-WWM-BiLSTM-CRF model employs RoBERTa as a pre-trained model, which has been trained on a larger corpus than BERT, resulting in higher computational resource and time requirements. Since the BCWC model already features a complex downstream network, it does not utilize RoBERTa as a pre-trained model. Nevertheless, BCWC achieves a slightly higher F1-score value after incorporating lexical information compared with RoBERTa-WWM-BiLSTM-CRF, demonstrating the effectiveness of including lexical information. Compared with the DSpERT model, the BCWC model outperforms it across all three datasets, validating its superior ability to extract contextual features and further confirming that lexical features can influence the accuracy of NER.
Additionally, in the Weibo and Youku datasets, LR-CNN, LGN, MTL-HWS, and KCB-FLAT all incorporated additional lexical information. The experimental results show that the BCWC model outperforms these models to varying degrees. The design of LR-CNN primarily aims to integrate a dictionary and fully utilize GPU parallelism. This method simulates all characters and potential words for sentence matching in parallel, employing a rethinking mechanism to feedback advanced features that resolve word conflicts. However, it focuses more on improving the recognition speed of NER rather than enhancing the model’s accuracy. LGN improves the RNN chain structure by introducing a dictionary-based global semantic graph neural network, addressing the limitations of the chain structure in capturing global semantic information when processing long texts or complex sentences. However, the frequent interactions among multiple graph information can result in a lack of internal semantics within compound vocabulary. In contrast, BCWC enhances the coupling between the segmentation of compound vocabulary using multi-scale dilated convolutions. Specifically, this approach tightly links long entities or compound words after segmentation. Experimental results indicate that BCWC achieves better accuracy. MTL-HWS recognizes that introducing vocabulary from a dictionary can introduce noise, so it employs a multi-task training approach to assist in word selection and filter out noisy vocabulary, thereby improving the accuracy of NER. This method is similar to BCWC, but the key difference lies in MTL-HWS’s word selection phase, where unavoidable erroneous vocabulary can negatively impact the main task of entity recognition. Providing incorrect information to a model in training can inevitably affect its precision, albeit slightly. The experimental results from the Weibo dataset show only a 0.48% difference. In contrast, BCWC avoids this issue by extracting lexical features from the segmentation data of each sample rather than relying on an external dictionary. In the best cases, some of the segments themselves may even be correct named entities. KCB-FLAT employs KVMN to extract syntactic information and introduces a bounded smoothing module combined with a regularity-awareness function to capture the internal regularities of each entity, reducing the model overconfidence in entity probabilities. However, this approach does not involve selection, which may lead to a decrease in the ability to recognize truly high-confidence entities in some cases, affecting the accuracy. Results from the CLUENER dataset indicate that the BCWC model outperforms this model by 2.23%. Since lexical information typically plays a crucial role in entity recognition, this demonstrates the effectiveness of the BCWC model in integrating lexical information.
The results of different models on the three datasets are shown in Fig. 9. It can be visually observed that the BCWC model achieved higher F1-score across all three datasets. In summary, our model consistently outperforms other models, likely attributed to its superior ability to extract lexical features and effectively fuse them through the use of multiple networks for feature extraction. To further substantiate the effectiveness of the proposed strategy in our model, we will conduct an ablation study in the subsequent analysis.
![]()
Figure 9.Results of different models on the three datasets.
4.3 Ablation study
The BCWC model not only integrates lexical information but also optimizes feature extraction using multi-scale IDCNN modules. To investigate the contribution of these strategies to the overall enhancement of the BCWC model, we conducted ablation experiments. By splitting the model into different module combinations, we observed the performance of these combinations in the experiments.
We divided the BCWC model into the following modules: Word module (WM), which represents the IDCNN-based lexical feature extraction module; multi-scale word module (MSWM), which introduces multi-scale iterative dilated convolutional networks for lexical feature extraction; character module (CM), representing the BiLSTM-based character feature extraction module; fully connected fusion (FCF), which uses a fully connected neural network to fuse character and lexical information; multi-head attention fusion (MHAF), which employs a multi-head attention mechanism for fusion. We also evaluated the impact of incorporating pre-trained models versus not using them. As shown in Table 5 (“+” represents that the method employs the pre-trained BERT model, while “−” indicates that it does not; bold entries mark the best performance in term of F1-score; the symbol “⊕” represents the combination of different modules), the data indicates that these strategies significantly enhance the model’s ability to effectively recognize Chinese named entities.
| Model | F1-score (%) | |||
| BERT | CLUENER | Youku | ||
| BCWC | + | |||
| CM | + | 76.81 (↓3.05) | 69.19 (↓4.41) | 85.79 (↓1.40) |
| − | 70.00 (↓9.86) | 56.58 (↓17.02) | 79.76 (↓7.43) | |
| WM | + | 76.48 (↓3.38) | 68.75 (↓4.85) | 85.46 (↓1.73) |
| MSWM | + | 76.72 (↓3.14) | 69.75 (↓3.85) | 85.64 (↓1.55) |
| CM⊕MSWM⊕FCF | + | 77.63 (↓2.23) | 70.39 (↓3.21) | 86.12 (↓1.07) |
| CM⊕WM⊕MHAF | + | 79.51 (↓0.35) | 73.07 (↓0.53) | 86.82 (↓0.37) |
Table 5.
When lexical information was removed and only character features were used, F1-score across all datasets dropped by an average of
Furthermore, the comparison of the final two module combinations in Table 5 demonstrates that the multi-head attention mechanism is more effective for fusing character and lexical features. By introducing dynamic weights that affect the internal relationships between characters and words, the model can better identify which characters contribute more to NER within a word. This helps the model understand which characters and words are the most crucial for the NER task.
In conclusion, the combination of multiple networks and multi-scale IDCNN plays a pivotal role in enhancing feature information within the model, leading to notable improvements in CNER performance. Both strategies individually contribute to the efficacy of the model, but their synergistic effect, when combined, yields the most favorable results. This underscores the importance of a comprehensive approach that leverages multiple perspectives and scales for feature extraction, ultimately enhancing the model’s ability to accurately identify and classify named entities in the text.
4.4 Structural advantage
Our proposed model exhibits flexibility by allowing for customization through adjustments to the size of the DCNN block for each IDCNN layer, as well as variations in the size of the convolutional kernel and the expansion rate within each DCNN block. To validate the efficacy of this adaptable approach, we conducted experiments using three distinct datasets with different structures in our model. This demonstrates the model’s versatility in accommodating diverse data structures and highlights its potential for optimization based on specific requirements and expectations.
Specifically, DCNN blocks of different sizes can achieve varying feature extraction effects on datasets of different scales. Larger DCNN blocks help capture deeper feature representations, making them suitable for tasks requiring complex contextual understanding, while smaller DCNN blocks are more appropriate for datasets of smaller scale or with simpler sentence structures. The dilation rate is also crucial in the BCWC model, as it determines the expansion of the convolutional kernel, thus affecting the receptive field at different scales. The model’s strength lies in its ability to adjust the dilation rate to accommodate varying contextual dependency needs. A low dilation rate helps capture local detail information, such as short-distance word relationships generated by compound word segmentation, while a high dilation rate is more suitable for long-distance dependencies, effectively handling complex contexts by capturing distant relationships between entities in long sentences or paragraphs, thereby improving the accuracy of entity recognition. Additionally, convolutional kernels of different scales can extract lexical information from multiple dimensions, enriching the feature representation. Small-scale convolutional kernels focus on processing local details and close word relationships, while large-scale kernels are better suited to capturing broader semantic information. When dealing with long entities or entity ambiguity, large-scale kernels can consider more contextual information to resolve these issues. The combination of different dilation rates and scales of convolutional kernels results in a multi-scale dilated convolution, creating a synergistic effect that enables the model to handle both coarse-grained and fine-grained features simultaneously.
We have designed the following structures.
Structure 1: Three layers of IDCNN with four DCNN blocks in each layer, where the convolutional kernel sizes of the IDCNN layers are the same and the expansion rate is 1, 1, 1, and 2 in that order.
Structure 2: Three layers of IDCNN with three DCNN blocks in each layer, where each IDCNN convolutional kernel size is 2, 3, and 4 in order, and the expansion rate is the same as that of Structure 1.
Structure 3: Two layers of IDCNN with three DCNN blocks in each layer, where the size of the convolutional kernel of each IDCNN layer is 3 and 4, the expansion rate of the DCNN block with convolutional kernel size of 3 is 1, 1, and 3, and the expansion rate of the DCNN block with convolutional kernel size of 4 is 1, 1, and 2 in that order.
Structure 4: The structure used in this paper, two-layer IDCNN with three DCNN blocks in each layer, where the DCNN blocks with the convolutional kernel size of 2 have expansion rates of 1, 1, and 3, and the DCNN blocks with the convolutional kernel size of 3 have expansion rates of 1, 1, and 2 in that order.
In the four different structures, we treated the DCNN blocks as variables, while keeping the dilation rate and kernel size constant. The results in Fig. 10 show that compared with the CLUENER dataset, which covers multiple domains, the content in the Weibo and Youku datasets is simpler. In both Structure 2 and Structure 3, the results outperform Structure 1, while on the CLUENER dataset, Structure 1 achieves better results. This suggests that larger DCNN blocks help in understanding more complex contexts. For Structure 3 and Structure 4, the only difference lies in the size of the convolutional kernels. Experimental results indicate that choosing an appropriate kernel size is crucial. For the three datasets highlighted in this paper, excessively large kernel sizes are not necessary. As shown in Table 1, the datasets do not involve a large amount of long texts but are more focused on local details and word relationships. Furthermore, the multi-scale design between layers ensures that issues related to entity ambiguity or long entities are effectively addressed.
![]()
Figure 10.Quantitative analysis of different structures: Results of IDCNN (a) with different structures on various datasets and (b) with the same structure but different convolutional kernel sizes on various datasets. In the notation
Overall, Structure 4 achieved superior performance across multiple datasets, especially in its adaptability to different task structures. As shown in Fig. 11, the experiments confirmed the significant advantage brought by the structural flexibility of the BCWC model in NER. These experimental results demonstrate that the flexibility and versatility of the BCWC model have been validated across various scenarios and data structures. Moreover, this flexibility serves as a foundation for introducing automated hyperparameter tuning strategies. Such strategies can further optimize the number of convolutional layers, dilation rates, and kernel sizes. By providing users with the best structural configuration, this reduces the complexity of manual parameter tuning, making the model more versatile and applicable across a broader range of tasks.
![]()
Figure 11.Comparison of different structures on three datasets.
In summary, multi-scale IDCNN of the BCWC model exhibits strong flexibility and adaptability. It can adjust the number of convolutional layers, dilation rates, and kernel sizes to meet the demands of various tasks, ensuring efficiency and accuracy in NER tasks. This structural advantage has not only been validated in experiments but also offers a broad application perspective for future multi-task learning and model optimization.
5 Conclusions
In this work, a comprehensive deep neural network framework tailored for CNER was proposed by introducing multi-scale IDCNN to optimize the extraction of lexical features. It involves embedding characters and words utilizing distinct pre-trained models, leveraging multiple networks to extract their feature information. Two fusion strategies were introduced and experimentally compared. The experimental results on three Chinese datasets demonstrate that the proposed model outperforms mainstream CNER models. They also indicate that integrating multi-scale lexical information improves recognition accuracy in CNER tasks. It means that capturing contextual information at multiple scales and effectively extracting lexical-level features are critical for CNER tasks in complex texts. This work theoretically addresses the problem of how to efficiently leverage lexical information in CNER. It also practically solves the technical challenge of efficiently extracting and integrating lexical features in large-scale, complex textual data, providing a more effective solution for real-world applications such as intelligent question-answering systems, automatic summarization, and information extraction. Moreover, our findings are consistent with some prior research, further confirming that effective fusion of multiple embeddings enhances the CNER performance. Furthermore, it should be noted that by introducing multi-scale IDCNN, we not only address the limitations of traditional single embedding models in handling complex contexts but also provide a more refined approach to feature fusion across different scales, improving the accuracy of CNER. This research offers an optimized solution for CNER tasks and contributes to the advancement of the field.
Despite the progress made, our model still has limitations. One key area that requires further research is how to handle extremely rare entities or emerging vocabulary that may not be adequately represented in pre-trained models. Additionally, while our model demonstrates good generalization across different datasets, it may still face challenges in more complex domains with high contextual ambiguity. Future research could explore more dynamic embedding techniques or incorporate external knowledge bases to further improve recognition capabilities in such cases.
APPENDIX A
There are some details about the experimental process using systems such as BERT, embedding layer, and multi-head attention that require fine-tuning of the hyperparameters, and some details about this process are given in Table A1 and Table A2. Some hardware and software environments about the experiments are given in Table A3.
| Hyperparameter | Value |
| RNN dimension | 64 |
| BERT learning rate | 2×10–5 |
| BERT dropout rate | 0.35 |
| RNN(CNN) learning rate | 1×10–3 |
| Kernel size | 3 |
| Boundary embedding dimension | 16 |
| BERT model | BERT-base-Chinese |
| Epoch | 30 |
| Optimizer | AdamW |
| Multi-head attention head | 8 |
Table 1. Some common hyperparameter settings about the experiments.
| Dataset | max_seq_len | Batch size | max_word_len |
| CLUENER | 128 | 32 | 25 |
| 64 | 16 | 20 | |
| Youku | 128 | 16 | 20 |
Table 2. Some hyperparameter settings about the experiments on the three datasets.
| Model | Precision (%) | Recall (%) | F1-score (%) |
| BiLSTM-CRF (2020) | 60.80 | 52.90 | 56.58 [ |
| Lattice-LSTM (2018) | 53.04 | 62.25 | 58.79 |
| LR-CNN (2019) | 57.14 | 66.67 | 59.92 |
| LGN (2019) | 56.44 | 64.52 | 60.21 |
| BERT-CRF (2019) | 67.12 | 66.88 | 67.00 [ |
| FGN (2021) | 69.02 | 73.65 | 71.25 |
| MTL-HWS (2023) | 73.03 | 73.21 | 73.12 |
| DSpERT (2023) | 69.52 | 68.80 | 69.12 |
| KCB-FLAT (2024) | 72.36 | 70.41 | 71.37 |
| LkLi-CNER (2023) | 77.43 | 68.23 | 72.54 |
| Ours | 71.96 | 75.32 | 73.60 |
Table 3. Performance on Weibo.
Disclosures
The authors declare no conflicts of interest.
References
[2] Yin D.-D., Cheng S.-Y., Pan B.-X., Qiao Y.-Y., Zhao W., Wang D.-Y.. Chinese named entity recognition based on knowledge based question answering system. Appl. Sci., 12, 5373:1-19(2022).
[3] Li J., Sun A.-X., Han J.-L., Li C.-L.. A survey on deep learning for named entity recognition. IEEE T. Knowl. Data En., 34, 50-70(2020).
[5] Hochreiter S., Schmidhuber J.. Long short-term memory. Neural Comput., 9, 1735-1780(1997).
[7] An Y., Xia X.-Y., Chen X.-L., Wu F.-X., Wang J.-X.. Chinese clinical named entity recognition via multi-head self-attention based BiLSTM-CRF. Artif. Intell. Med., 127, 102282:1-12(2022).
[9] Seti X., Wumaier A., Yibulayin T., Paerhati D., Wang L.-L., Saimaiti A.. Named-entity recognition in sports field based on a character-level graph convolutional network. Information, 11, 30:1-16(2020).
[10] Deng Z.-R., Tao Y., Lan R.-S., Yang R., Wang X.-Y.. Kcr-FLAT: A Chinese-named entity recognition model with enhanced semantic information. Sensors, 23, 1771:1-15(2023).
[13] Wang X.-L., Xu X.-R., Huang D.-G., Zhang T.. Multi-task label-wise transformer for Chinese named entity recognition. ACM T. Asian Low-Reso., 22, 118:1-15(2023).
[14] Yan Y.-B., Zhu P., Cheng D.-W., Yang F.-Z., Luo Y.-F.. Adversarial multi-task learning for efficient Chinese named entity recognition. ACM T. Asian Low-Reso., 22, 193:1-19(2023).
[15] Liu Q.-P., Zhang L.-L., Ren G., Zou B.-J.. Research on named entity recognition of Traditional Chinese Medicine chest discomfort cases incorporating domain vocabulary features. Comput. Biol. Med., 166, 107466:1-6(2023).
[16] Nasar Z., Jaffry S.W., Malik M.K.. Named entity recognition and relation extraction: State-of-the-art. ACM Comput. Surv., 54, 20:1-39(2022).
[17] J. Lafferty, A. McCallum, F.C.N. Pereira, Conditional rom fields: Probabilistic models f segmenting labeling sequence data, in: Proc. of the 18th Intl. Conf. on Machine Learning, Williamstown, USA, 2001, pp. 282–289.
[18] Li W., Zhao D.-Z., Li B., Peng X.-M., Liu J.-R.. Combining CRF and rule based medical named entity recognition. Appl. Res. Comput., 32, 1082-1086(2015).
[19] N.V. Sobhana, P. Mitra, S.K. Ghosh, Conditional rom field based named entity recognition in geological text, Int. J. Comput. Appl. 1 (3) (2010) 119–125.
[20] E. Strubell, P. Verga, D. Belanger, A. McCallum, Fast accurate entity recognition with iterated dilated convolutions, in: Proc. of the Conf. on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 2017, pp. 2670–2680.
[21] Chen T.-Y., Feng S.. Research on named entity recognition method and model stability of electronic medical record based on IDCNN+CRF and attention mechanism. China Digital Medicine, 17, 1-5(2022).
[22] Hu H.-Y., Zhao C.-P., Ma L., Jiang H.-Z., Zhang J., Zhu W.-G.. Study on Chinese medical named entity recognition based on the dilated convolutional neural network. Journal of Medical Informatics, 42, 39-44(2021).
[23] Zhao J.-Q., Zhu W.-T., Chen C.. Named entity recognition based on duplex convolution neural network model. Computer Technology and Development, 33, 187-192(2023).
[24] J. Devlin, M.W. Chang, K. Lee, K. Toutanova, BERT: Pretraining of deep bidirectional transfmers f language understing, in: Proc. of the Conf. of the Nth American Chapter of the Association f Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019, pp. 4171–4186.
[25] A. Radfd, K. Narasimhan, T. Salimans, I. Sutskever, Improving language understing by generative pretraining, Openai Blog, [Online]. Available, https:gwern.docwwws3uswest2.amazonaws.comd73fdc5ffa8627bce44dcda2fc012da638ffb158.pdf, 2018.
[26] Z.J. Dai, X.T. Wang, P. Ni, Y.M. Li, G.M. Li, X.M. Bai, Named entity recognition using BERT BiLSTM CRF f Chinese electronic health recds, in: Proc. of the 12th Intl. Congress on Image Signal Processing, BioMedical Engineering Infmatics, Suzhou, China, 2019, pp. 1–5.
[27] Yu Y.-Q., Wang Y.-Z., Mu J.-Q. et al. Chinese mineral named entity recognition based on BERT model. Expert Syst. Appl., 206, 117727:1-9(2022).
[28] S.H. Wang, X.F. Sun, X.Y. Li, et al., GPTNER: Named entity recognition via large language models [Online]. Available, https:arxiv.gabs2304.10428, October 2023.
[29] Yan H., Li Y., Lei Q.-X., Wang X.. Chinese named entity recognition method based on lexical information features. Journal of Chinese Computer Systems, 45, 1622-1628(2024).
[30] Yang Z.-W., Ma J., Chen H.-C., Zhang J.-W., Chang Y.. Context-aware attentive multilevel feature fusion for named entity recognition. IEEE T. Neur. Net. Lear., 35, 973-984(2024).
[31] Long K.-F., Zhao H., Shao Z.-Z. et al. Deep neural network with embedding fusion for Chinese named entity recognition. ACM T. Asian Low-Reso., 22, 91:1-16(2023).
[32] Wang Y., Wang Z., Yu H., Wang G.-Y., Lei D.-J.. The interactive fusion of characters and lexical information for Chinese named entity recognition. Artif. Intell. Rev., 57, 258:1-21(2024).
[33] Li M.-J., Huang R.-Q., Qi X.-X.. Chinese clinical named entity recognition using multi-feature fusion and multi-scale local context enhancement. Comput. Mater. Con., 80, 2283-2299(2024).
[34] Qiu Q.-J., Tian M., Huang Z. et al. Chinese engineering geological named entity recognition by fusing multi-features and data enhancement using deep learning. Expert Syst. Appl., 238, 121925:1-17(2024).
[35] L. Xu, Y. Tong, Q.Q. Dong, et al., CLUENER2020: Finegrained named entity recognition dataset benchmark f Chinese [Online]. Available, https:arxiv.gabs2001.04351, January 2020.
[36] N.Y. Peng, M. Dredze, Named entity recognition f Chinese social media with jointly trained embeddings, in: Proc. of the Conf. on Empirical Methods in Natural Language Processing, Lisbon, Ptugal, 2015, pp. 548–554.
[37] Z.M. Jie, P.J. Xie, W. Lu, R.X. Ding, L.L. Li, Better modeling of incomplete annotations f named entity recognition, in: Proc. of the Conf. of the Nth American Chapter of the Association f Computational Linguistics: Human Language Technologies, Minneapolis, USA, 2019, pp. 729–734.
[38] S. Li, Z. Zhao, R.F. Hu, W.S. Li, T. Liu, X.Y. Du, Analogical reasoning on Chinese mphological semantic relations, in: Proc. of the 56th Annual Meeting of the Association f Computational Linguistics, Melbourne, Australia, 2018, pp. 138–143.
[39] T. Mikolov, I. Sutskever, K. Chen, G.S. Crado, J. Dean, Distributed representations of wds phrases their compositionality, in: Proc. of the 26th Intl. Conf. on Neural Infmation Processing Systems, Lake Tahoe, USA, 2013, pp. 3111–3119.
[40] Y. Goldberg, O. Levy, wd2vec explained: Deriving Mikolov et al.’s negativesampling wdembedding method [Online]. Available, https:arxiv.gabs1402.3722, February 2014.
[41] X.W. Yin, S. Zheng, Q.M. Wang, Finegrained Chinese named entity recognition based on RoBERTaWWMBiLSTMCRF model, in: Proc. of the 6th Intl. Conf. on Image, Vision Computing, Qingdao, China, 2021, pp. 408–413.
[42] S.Q. Li, J.J. Zeng, J.H. Zhang, T. Peng, L. Yang, H.F. Lin, ALBERTBiLSTM f sequential metaph detection, in: Proc. of the Second Wkshop on Figurative Language Processing, Virtual Event, 2020, pp. 110–115.
[43] Y.H. Zhai, S.W. Tian, L. Yu, et al., Chinese acters Pinyin: A model with two parallel feature extracts f Chinese entity recognition [Online]. Available, https:www.researchsquare.comarticlers2282745v1, November 2022.
[44] Z.Y. Xuan, R. Bao, S.Y. Jiang, FGN: Fusion glyph wk f Chinese named entity recognition, in: Proc. of the Knowledge Graph Semantic Computing: Knowledge Graph Cognitive Intelligence: 5th China Conf., Nanchang, China, 2021, pp. 28–40.
[45] Y. Zhang, J. Yang, Chinese NER using lattice LSTM, in: Proc. of the 56th Annual Meeting of the Association f Computational Linguistics, Melbourne, Australia, 2018, pp. 1554–1564.
[46] L.Z. Li, S. Zheng, Q.M. Wang, RoBERTa stacked bidirectional GRU f finegrained Chinese named entity recognition, in: Proc. of the 6th Intl. Conf. on Mathematics Artificial Intelligence, Chengdu, China, 2021, pp. 95–100.
[47] T. Gui, R.T. Ma, Q. Zhang, L.J. Zhao, Y.G. Jiang, X.J. Huang, CNNbased Chinese NER with lexicon rethinking, in: Proc. of the 28th Intl. Joint Conf. on Artificial Intelligence, Macao, China, 2019, pp. 4982–4988.
[48] T. Gui, Y.C. Zou, Q. Zhang, et al., A lexiconbased graph neural wk f Chinese NER, in: Proc. of the Conf. on Empirical Methods in Natural Language Processing the 9th Intl. Joint Conf. on Natural Language Processing, Hong Kong, China, 2019, pp. 1040–1050.
[49] Zhang M., Lu L.. A local information perception enhancement-based method for Chinese NER. Appl. Sci., 13, 9948:1-19(2023).
[50] Deng Z.-R., Huang Z., Wei S.-W., Zhang J.-L.. KCB-FLAT: Enhancing Chinese named entity recognition with syntactic information and boundary smoothing techniques. Mathematics, 12, 2714:1-18(2024).
[51] Y.H. Yuan, Q.H. Zhang, X. Zhou, M. Gao, A Chinese named entity recognition model: Integrating label knowledge lexicon infmation, Int. J. Mach. Learn. Cyb. (May 2024), doi: 10.1007s13042024022072.
[52] E.W. Zhu, Y.Y. Liu, J.P. Li, Deep span representations f named entity recognition, in: Proc. of the Findings of the Association f Computational Linguistics, Tonto, Canada, 2023, pp. 10565–10582.
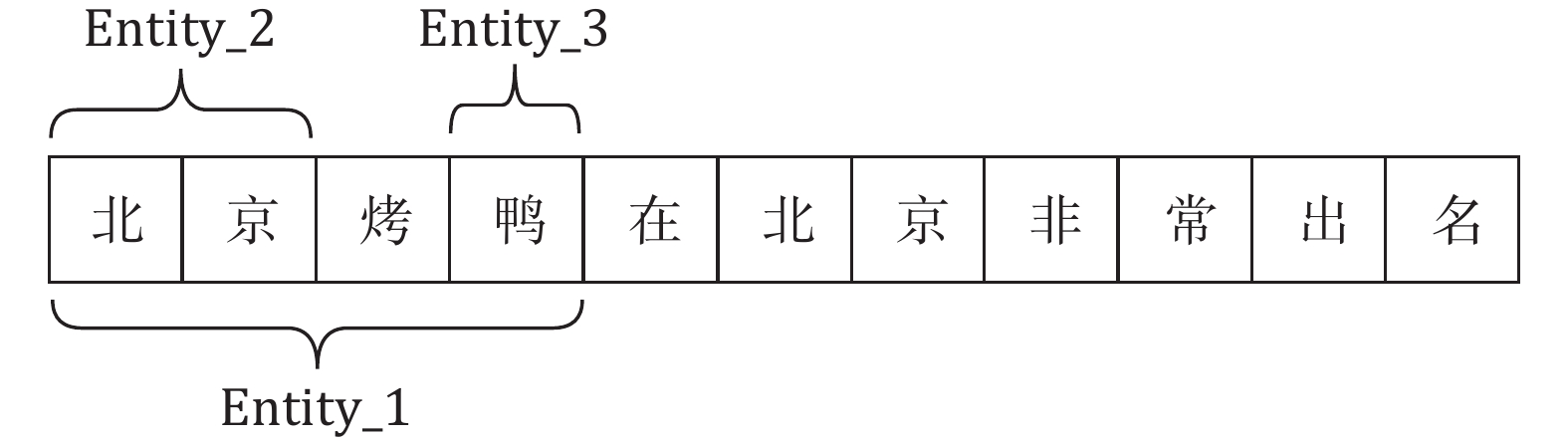


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20