AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence
Place recognition is designed to help a robot or a navigation system determine if it is in a previously visited location. Specifically, it involves querying the image or LiDAR point clouds of the local scene of a given robot or a navigation system to find the best match within the acquired sequence data. Position recognition is a key step to eliminating the accumulated errors of robot motion over time and restoring high-precision maps. It is often used in dynamic real-time positioning and mapping, virtual reality technology, automatic driving, and other fields. Place recognition can be divided into two categories: visual and laser. LiDAR 3D point cloud data effectively mitigates the influence of lighting and seasonal changes, which makes it suitable for large-scale, complex scenes. However, it faces challenges such as occlusion and large viewing angles. Although methods like PointNetVLAD have made progress in point cloud processing by extracting the global descriptor of a single-frame point cloud, they ignore the correlation between different clouds in the feature pooling stage. These methods mainly rely on the powerful NetVLAD clustering network for point cloud classification. However, NetVLAD has a large number of parameters and is computationally complex, which seriously affects operational efficiency. Therefore, this paper proposes a deep learning-based place recognition method that uses feature fusion. In this method, two frames of point clouds are regarded as a new point cloud, and by aggregating the features of the point clouds, the method determines whether the two frames represent the same place. The key innovation of this method lies in the design of the feature enhancement module, which effectively extracts the relevant information between the two frames of point clouds. Additionally, to improve operational efficiency, this paper employs a lightweight feature aggregation network to achieve faster processing while maintaining high precision.
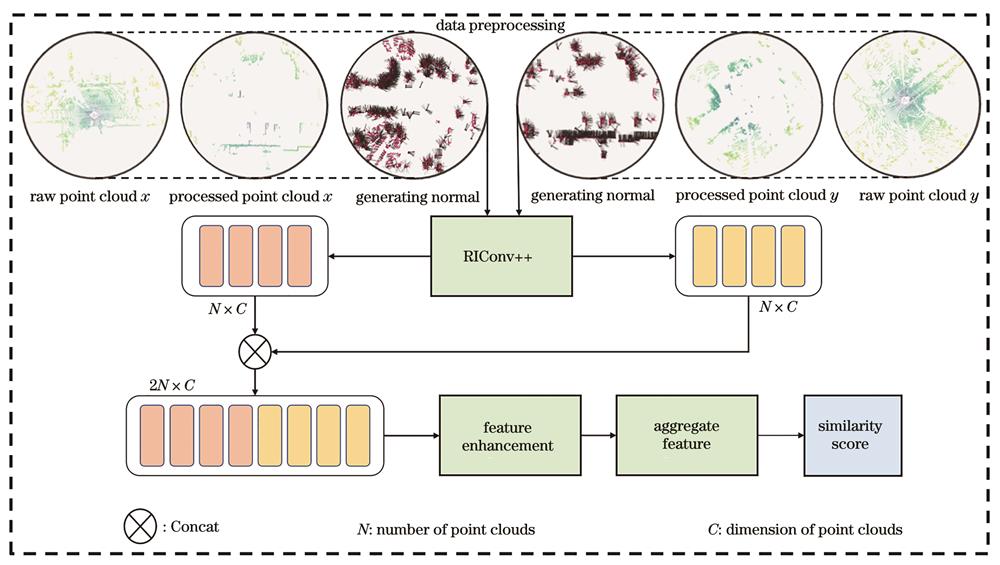
We propose a LiDAR point cloud place recognition network based on feature fusion. The network is mainly divided into four steps. Firstly, two point clouds are preprocessed, which includes downsampling and ground filtering. Next, feature extraction is carried out to obtain the local features of each point cloud. The local features are then regarded as the local features of a new point cloud (z), and the new local features are weighted by the feature enhancement module. Afterward, the feature aggregation network is used to aggregate the local features of the new point cloud (z) into global features. Finally, the global descriptor is normalized through a full join to obtain the similarity score.
As shown in Table 1, the Our-MV method and Our-NV method show superior performance compared to all other methods. In contrast, the two traditional methods, SC and M2DP, which are capable of describing the global characteristics of the point cloud, do not perform as well as deep learning methods in terms of generalization. For example, in the 02 sequence, due to severe occlusion in most point clouds, the performance of the SC method is suboptimal, with an accuracy of only 0.858. In the 08 sequence, due to the existence of a large-scale reverse closed-loop, the SC method also performs poorly, achieving an accuracy of only 0.811. This is mainly because the SC method mainly focuses on the top view of the point cloud, neglecting details from other angles, which results in the loss of many key features during projection. When comparing the Our-MV and Our-NV methods, it can be found that Our-MV outperforms Our-NV in each sequence and overall accuracy. This is mainly because MixVPR accounts for long-term feature relationships during feature aggregation, while NetVLAD focuses more on local features. Therefore, Our-MV can capture the characteristic information of point clouds more comprehensively. Figure 6 shows the accuracy-recall curves for the comparison methods. The method proposed in this paper maintains stable accuracy across different thresholds, which fully demonstrates its high performance in distinguishing between positive and negative samples. According to the visualization results in Figs. 7 and 8, it can be seen that the performance of the Our-MV method is superior to that of Our-NV in different scenes, which confirms the effectiveness of our changes. The ablation experiment in Table 2 fully reflects the effectiveness of the feature enhancement module. In addition, as shown in Table 3, the number of parameters in the Our-MV method is reduced by up to 73.88%, and the processing time is slightly decreased (by about 7%). Table 4 shows the effects of the proposed method under different thresholds, which illustrates that the proposed method is robust to changes in the distance threshold.
In this paper, we propose a feature fusion-based deep learning place recognition method. In this method, two frame point clouds are regarded as a single point cloud, and by aggregating features from the point clouds, the method determines whether the two frame point clouds represent the same place. The key innovation of this method lies in the design of the feature enhancement module, which effectively extracts the relevant information between the two frame point clouds. Moreover, to improve operational efficiency, we also adopt a lightweight feature aggregation network to achieve faster processing while maintaining high precision. However, the loss function adopted in this paper is mainly a global optimization function, which imposes relatively weak constraints on the features of local key points. During global optimization, the model may ignore the influence of local features in the learning process, potentially affecting the accuracy of place recognition. To further improve the model's performance, we plan to explore increasing the model's complexity in future research and consider incorporating a local feature similarity loss function to enhance the accuracy of local feature extraction.