Journals >Laser & Optoelectronics Progress
Contents

2025
Volume: 62 Issue 8
20 Article(s)
Export citation format
Digital Image Processing
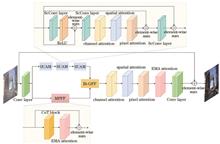
Image Dehazing Algorithm Based on Multi-Dimensional Attention Feature Fusion
Xuguang Zhu, and Nan Jiang
To address the problems of detail loss and color distortion in the current image defogging algorithms, this paper proposes a multi-dimensional attention feature fusion image dehazing algorithm. The core step of the proposed algorithm is the introduction of a union attention mechanism module, which can simultaneously opTo address the problems of detail loss and color distortion in the current image defogging algorithms, this paper proposes a multi-dimensional attention feature fusion image dehazing algorithm. The core step of the proposed algorithm is the introduction of a union attention mechanism module, which can simultaneously operate in three dimensions of channel, space, and pixel to achieve accurate enhancement of local features, while parallel a multi-scale perceptual feature fusion module effectively captures global feature information of different scales. To achieve a more refined and accurate dehazing effect, a bi-directional gated feature fusion mechanism is added to the proposed algorithm to realize the deep fusion and complementarity of local information and global information features. Experimental validation on multiple datasets, such as RESIDE, I-Hazy, and O-Hazy shows that, the proposed algorithm exhibits better performance than the existing state-of-the-art in terms of peak signal-to-noise ratio (PSNR) and structural similarity (SSIM). Compared with the classical GCA-Net, the PSNR and SSIM of the proposed algorithm increased by 2.77 dB and 0.0046, respectively. Results of this study can provide new insights and directions for investigating image dehazing algorithms..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0837004 (2025)

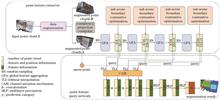
Weakly-Supervised Point Cloud Semantic Segmentation with Consistency Constraint and Feature Enhancement
Dong Wei, Yifan Bai, He Sun, and Jingtian Zhang
To address issues such as poor output consistency, information loss, and blurred boundaries caused by incomplete truth labeling in current weakly-supervised point cloud semantic segmentation methods, a weakly-supervised point cloud semantic segmentation method with input consistency constraint and feature enhancement iTo address issues such as poor output consistency, information loss, and blurred boundaries caused by incomplete truth labeling in current weakly-supervised point cloud semantic segmentation methods, a weakly-supervised point cloud semantic segmentation method with input consistency constraint and feature enhancement is proposed. Additional constraint is provided on the input point cloud to learn the input consistency of the augmented point cloud data, in order to better understand the essential features of the data and improve the generalization ability of the model. An adaptive enhancement mechanism is introduced in the point feature extractor to enhance the model's perceptual ability, and utilizing sub scene boundary contrastive optimization to further improve the segmentation accuracy of the boundary region. By utilizing query operations in point feature query network, sparse training signals are fully utilized, and a channel attention mechanism module is constructed to enhance the representation ability of important features by strengthening channel dependencies, resulting in more effective prediction of point cloud semantic labels. Experimental results show that the proposed method achieves good segmentation performance on three public point cloud datasets of S3DIS, Semantic3D, and Toronto3D, with a mean intersection over union of 66.4%, 77.9%, and 80.5%, respectively, using 1.0% truth labels for training..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0837006 (2025)
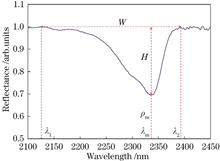
Study on the Decision Tree Model for Carbonate Rock Lithology Identification Based on Hyperspectral Data
Yu Huang, Yanlin Shao, Wei Wei, and Qihong Zeng
Hyperspectral remote sensing has been widely applied in geological research due to its rich multi-band spectral information. Most studies mainly focus on the identification of soil components and clay minerals, with relatively fewer studies on carbonate rocks, so this paper proposes a decision tree model to achieve preHyperspectral remote sensing has been widely applied in geological research due to its rich multi-band spectral information. Most studies mainly focus on the identification of soil components and clay minerals, with relatively fewer studies on carbonate rocks, so this paper proposes a decision tree model to achieve precise classification of carbonate rocks based on hyperspectral data. A continuum-removed method is used to preprocess the data, and then combines spectral knowledge and machine learning to extract features. Specifically, the study determines spectral intervals closely related to carbonate rocks through spectral knowledge and extracts key waveform features from the spectral curves. Subsequently, the study uses the random forest algorithm to select features with discriminative capabilities, determines the optimal classification discriminant through threshold analysis, and builds a decision tree model. Finally, the model performance is evaluated using a confusion matrix, and the classification accuracy is compared with other five models. Results show that the decision tree model constructed based on the order of the lowest point wavelength of the absorption valley, the right shoulder wavelength of the absorption band , and the absorption bandwidth exhibited the highest classification accuracy, with an accuracy rate of 95.57%..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0837007 (2025)
Improved 3D Reconstruction Algorithm for Unmanned Aerial Vehicle Images Based on PM-MVS
Peixin He, Xiyan Sun, Yuanfa Ji, Yang Bai, and Yu Chen
To address the challenges of long reconstruction time and numerous model voids in large-scale scenes and weakly textured regions during 3D reconstruction of unmanned aerial vehicle (UAV) images using existing multi-view stereo reconstruction (MVS) algorithms, an improved 3D reconstruction algorithm based on PatchMatch To address the challenges of long reconstruction time and numerous model voids in large-scale scenes and weakly textured regions during 3D reconstruction of unmanned aerial vehicle (UAV) images using existing multi-view stereo reconstruction (MVS) algorithms, an improved 3D reconstruction algorithm based on PatchMatch MVS (PM-MVS), called MCP-MVS, is proposed. The algorithm employs a multi-constraint matching cost computation method to eliminate outlier points from the 3D point cloud, thereby enhancing robustness. A pyramid red-and-black checkerboard sampling propagation strategy is introduced to extract geometric features across different scale spaces, while graphics processing unit based parallel propagation is exploited to improve the reconstruction efficiency. Experiments conducted on three UAV datasets demonstrate that MCP-MVS improves reconstruction efficiency by at least 16.6% compared to state-of-the-art algorithms, including PMVS, Colmap, OpenMVS, and 3DGS. Moreover, on the Cadastre dataset, the overall error is reduced by 35.7%, 20.3%, 19.5%, and 11.6% compared to PMVS, Colmap, OpenMVS, and 3DGS, respectively. The proposed algorithm also achieves the highest F-scores on the Cadastre and GDS datasets, 75.76% and 79.02%, respectively. These results demonstrate that the proposed algorithm significantly reduces model voids, validating its effectiveness and practicality..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0837009 (2025)
Imaging Systems

Design of Image-Acquisition System for I-ToF Image Sensor Based on FPGA
Qian Wan, Jiangtao Xu, Quanmin Chen, Zijian Liu, and Yijie Zhang
As conventional image-acquisition systems cannot easily fulfill the demand for rapid transmission of significant data amounts from indirect time-of-flight (I-ToF) image sensors, a high-speed image-acquisition system based on a field-programmable gate array (FPGA) and multilane camera serial interface 2 (CSI-2) is propoAs conventional image-acquisition systems cannot easily fulfill the demand for rapid transmission of significant data amounts from indirect time-of-flight (I-ToF) image sensors, a high-speed image-acquisition system based on a field-programmable gate array (FPGA) and multilane camera serial interface 2 (CSI-2) is proposed. Based on the CSI-2 protocol, the system adopts a digital physical layer with 12 independent lanes, which can significantly improve the acquisition rate of sensor data. Simultaneously, the system utilizes the short-packet information of the CSI-2 protocol to denote different phase-shift images output by the I-ToF sensor, thus enabling the host computer to reconstruct depth images accurately. In the FPGA design, the low level protocol layer module is designed based on a parallel architecture to process CSI-2 data packets at high speed. Additionally, a parallel first-in first-out (FIFO) structure is adopted to eliminate delays between different data lanes. Experimental results show that the system can support the complete acquisition of I-ToF image sensor data with a 2016 pixel×1096 pixel resolution and 30 frame/s frame rate. In the high-speed burst mode of the CSI-2, the instantaneous bandwidth of the FPGA data acquisition can reach a maximum of 9.600 Gb/s. The depth image reconstructed by the host computer enables distance measurement. Therefore, the image-acquisition system based on FPGA and multilane CSI-2 enables high-speed I-ToF image-sensor data transmission..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0811003 (2025)

Surface Structured Light Decoding Algorithm Based on Illumination Intensity
Jiaxuan Han, Yi Qian, Yang Yang, and Shigang Liu
To address the problem wherein the existing decode methods do not consider the effect of global illumination on decoding accuracy, this paper proposes a surface structured light decoding algorithm based on illumination intensity. First, the appropriate subhigh-frequency patterns from a series of encoded patterns are seTo address the problem wherein the existing decode methods do not consider the effect of global illumination on decoding accuracy, this paper proposes a surface structured light decoding algorithm based on illumination intensity. First, the appropriate subhigh-frequency patterns from a series of encoded patterns are selected to estimate the ratio coefficient of the direct and global illumination intensities for a scene. Subsequently, the ratio coefficient is used to compute the direct and global light intensities of each pixel point. Finally, a decoding rule is constructed based on the direct and global light intensities, followed by three-dimensional reconstruction. Comparative experimental results show that the proposed decoding algorithm can effectively improve both the decoding accuracy and quality of the reconstructed point cloud..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0811004 (2025)
Wider Field of View Imaging Method in Super-Resolution Microscopy Based on Square Aperture
Bowen Liu, Junkang Dai, Zhen'an Fu, Zitong Jin... and Yi Jin|Show fewer author(s)
In the field of microscopy, achieving a wider field of view and higher resolution are two critical goals pursued by researchers. Structured illumination microscopy (SIM) has effectively addressed the demand for higher resolution by surpassing the optical diffraction limit. However, limitations in beam range within struIn the field of microscopy, achieving a wider field of view and higher resolution are two critical goals pursued by researchers. Structured illumination microscopy (SIM) has effectively addressed the demand for higher resolution by surpassing the optical diffraction limit. However, limitations in beam range within structured illumination systems often cause pixel aliasing image artifacts when increasing the field of view. To eliminate these artifacts, we combine the coded aperture imaging technique, commonly used in computational imaging, with structured illumination microscopy, thereby proposing a super-resolution microscopy method that utilizes a square aperture to enhance the field of view. The square aperture is used to recover mixed frequency domain information in images captured with a 60× objective lens, ultimately reconstructing images that achieve the same resolving power as a 100× objective lens while attaining a fourfold increase in the field of view. The effectiveness of this method is demonstrated through both simulated and actual imaging data. This study provides a novel approach for enhancing the field of view in super-resolution structured illumination microscopy systems..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0811006 (2025)
Instrumentation, Measurement and Metrology
Failure Detection Algorithm for Electric Multiple Unit Brake Disc Bolts Based on SSD-YOLO
Yehong Chen, Hang Zhou, Xin Lu, Jia Yu... and Kewei Song|Show fewer author(s)
Manual failure detection in the train of electric multiple unit (EMU) failure detection system (TEDS) involves high error rates and significant workload. To address this problem, this paper proposes an SSD-YOLO algorithm for detection of EMU brake disc bolts failures, which is improved from YOLOv5n. The network structuManual failure detection in the train of electric multiple unit (EMU) failure detection system (TEDS) involves high error rates and significant workload. To address this problem, this paper proposes an SSD-YOLO algorithm for detection of EMU brake disc bolts failures, which is improved from YOLOv5n. The network structure of YOLOv5n is improved considering that the failure areas of brake disc bolts are small and the failures are similar to that of normal samples. To make the model flexibly adapt to the features of different scales and enlarge the receptive field, the down sampling convolution layers in the backbone network are replaced with switchable atrous convolution layers. To enhance the ability of the network to obtain global information and interact with contextual information, this study integrates the Swin-Transformer module at the end of the backbone network. To better deal with semantic information of different scales and resolutions, the coupled detection head of the YOLO series is replaced with an efficient decoupled head, which can extract target location and category information. To further improve the training convergence speed of the algorithm, the SCYLLA-intersection over union (SIoU) loss function, which has better positioning ability, is used to replace the CIoU loss function. In this study, artificially annotated samples of the EMU brake disc bolts are used to train the network. Experiments show that the detection mean average precision (mAP) value of the improved algorithm on the EMU brake disc bolts failure dataset increased by 6.8 percentage points to 98.3%, compared with 91.5% of the original YOLOv5n model. A detection frame rate of 89 frame/s is achieved on the RTX3090 graphics card, which is 1.7 times that of YOLOv5l and 3.7 times that of YOLOX-S, meeting the real-time requirement of TEDS failure detection. The SSD-YOLO algorithm can quickly detect the missing failures of the EMU brake disc bolts, reduces the manual workload of analysts, and provides a reference for future research on condition maintenance of EMU..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0812001 (2025)
Machine Vision
Lidar SLAM Algorithm Based on Point Cloud Geometry and Intensity Information
Long Peng, Weigang Li, Qifeng Wang, and Huan Yi
To address the low accuracy of the laser simultaneous localization and mapping (SLAM) algorithm in large scenes, this paper proposes a lidar SLAM algorithm based on point cloud geometry and intensity information. First, point cloud geometry and intensity information are combined for feature extraction, where weighted iTo address the low accuracy of the laser simultaneous localization and mapping (SLAM) algorithm in large scenes, this paper proposes a lidar SLAM algorithm based on point cloud geometry and intensity information. First, point cloud geometry and intensity information are combined for feature extraction, where weighted intensity is introduced in the calculation of local smoothness to enhance the robustness of feature extraction. Subsequently, a rectangular intensity map is introduced to construct intensity residuals, whereas geometric and strength residuals are integrated to optimize pose estimation, thereby improving mapping accuracy. Finally, a feature descriptor based on point cloud geometry and intensity information is introduced in the loop detection process, thus effectively enhancing the loop recognition accuracy. Experimental results on public datasets show that, compared with the current mainstream LeGO-LOAM algorithm, the proposed algorithm offers greater position accuracy..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815001 (2025)
Lightweight Small Object Detection Algorithm Based on STD-DETR
Zeyu Yin, Bo Yang, Jinling Chen, Chuangchuang Zhu... and Jin Tao|Show fewer author(s)
To address the challenges of small target detection in aerial photography images by unmanned aerial vehicle, including complex background, tiny and dense targets, and difficulties in deploying models on mobile devices, this paper proposes an improved lightweight small target detection algorithm based on real-time DEtecTo address the challenges of small target detection in aerial photography images by unmanned aerial vehicle, including complex background, tiny and dense targets, and difficulties in deploying models on mobile devices, this paper proposes an improved lightweight small target detection algorithm based on real-time DEtection TRansformer (RT-DETR) model, named STD-DETR. First, RepConv is introduced to improve the lightweight Starnet network, replacing the original backbone network, thereby achieving lightweight. A novel feature pyramid is then designed, incorporating a 160 pixel × 160 pixel feature map output at the P2 layer to enrich small target information. This approach replaces the traditional method of adding a P2 small target detection head, and introduces the CSP-ommiKernel-squeeze-excitation (COSE) module and space-to-depth (SPD) convolution to enhance the extraction of global features and the fusion of multi-scale features. Finally, pixel intersection over union (PIoU) is used to replace the original model's loss function, calculating IoU at the pixel level to more precisely capture small overlapping regions, reducing the miss rate and improving detection accuracy. Experimental results demonstrate that, compared with baseline model, the STD-DETR model achieves improvements of 1.3 percentage points, 2.2 percentage points, and 2.3 percentage points in accuracy, recall, and mAP50 on the VisDrone2019 dataset, while reducing computational cost and parameters by ~34.0% and ~37.9%, respectively. Generalization tests on the Tinyperson dataset show increases of 3.7 percentage points in accuracy and 3.1 percentage points in mAP50, confirming the model's effectiveness and generalization capability..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815002 (2025)
Improved RRU-Net for Image Splicing Forgery Detection
Ying Ma, Yilihamu Yaermaimaiti, Shuoqi Cheng, and Yazhou Su
To address the problem that feature extraction by increasing the depth in image splicing forgery detection algorithm based on convolutional neural network (CNN) can easily lead to loss of shallow forgery trace features, which causes a decrease in image resolution, this paper proposes an improved ringed residual U-net (To address the problem that feature extraction by increasing the depth in image splicing forgery detection algorithm based on convolutional neural network (CNN) can easily lead to loss of shallow forgery trace features, which causes a decrease in image resolution, this paper proposes an improved ringed residual U-net (RRU-Net) dual-view multiscale image splicing forgery detection algorithm. First, the noise image is generated by multifield fusion, and the noise perspective is generated through the high-pass filter of the spatial rich model (SRM), to enhance edge information learning. Second, the multiscale feature extraction module is designed by combining the original view with continuous downsampling of the noisy view to obtain the multiscale semantic information of the image. Finally, the A2-Nets dual-attention network is introduced to effectively capture the global information and accurately locate the tampered area of ??the image. Compared with the original RRU-Net, the algorithm in this study shows a significant detection effect and robustness improvement on multiple data sets, demonstrating significant progress in the field of image forgery detection. These results show that the proposed method has higher accuracy and reliability when dealing with complex scenes and diversified data, providing important technical support for research and application in the field of image security and information protection..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815006 (2025)
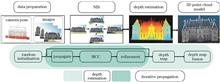
Self-Supervised Monocular Depth Estimation Model Based on Global Information Correlation Under Influence of Local Attention
Lei Xiao, Peng Hu, and Junjie Ma
Current methods for estimating monocular depth based on global attention mechanisms excel in capturing long-range dependencies, however, they often have drawbacks of high computational complexity and numerous parameters. Additionally, these methods can be susceptible to interference from irrelevant regions, which reducCurrent methods for estimating monocular depth based on global attention mechanisms excel in capturing long-range dependencies, however, they often have drawbacks of high computational complexity and numerous parameters. Additionally, these methods can be susceptible to interference from irrelevant regions, which reduces their ability to accurately estimate fine details. This study proposes a self-supervised monocular depth estimation model based on a local attention mechanism, which further leverages convolution and Shuffle operations for global information interaction. The proposed method first calculates attention within divided local windows and then effectively integrates global information by combining depthwise separable convolutions and Shuffle operations across spatial and channel dimensions. Experimental results on the public KITTI dataset demonstrate that the proposed method significantly reduces computational complexity and parameter count and improves the ability to handle depth details, outperforming mainstream methods based on global attention mechanisms..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815010 (2025)
Stereo Matching Algorithm Based on Adaptive Spatial Convolution
Fanna Meng, ZouYongjia, Yang Cao, Jin Lü, and Hongfei Yu
Stereo matching, a significant research focus in computer vision, has wide-ranging applications in fields such as autonomous driving, medical imaging, and robotic navigation. To address the issue of poor matching performance in ill-posed regions within image sequences, this paper presents a stereo matching algorithm baStereo matching, a significant research focus in computer vision, has wide-ranging applications in fields such as autonomous driving, medical imaging, and robotic navigation. To address the issue of poor matching performance in ill-posed regions within image sequences, this paper presents a stereo matching algorithm based on adaptive spatial convolution. Initially, an adaptive spatial convolution block is incorporated into the context network. Through weighted aggregation of multiple convolution kernel responses, the context network's capability to capture pathological regions in complex scenes is enhanced, achieving accurate feature representation. Attention maps of the input features are then obtained along the channel dimension. Subsequently, the algorithm uses a multiscale gated recurrent unit (GRU) network structure to optimize the initial disparity results, and the attention maps generated by adaptive spatial convolution are employed to weight the GRU's output, effectively suppressing noise and further improving the accuracy of disparity estimation. Experimental results show that the proposed algorithm achieves an average endpoint error of 0.46 pixel on the Scene Flow dataset, reducing the error by 14.81% compared to benchmark methods. On the KITTI dataset, it achieves a 3-pixel error rate of 1.40% across all regions, a 15.66% reduction compared to benchmark methods, and delivers superior disparity estimation performance. Notably, in ill-posed scenarios such as occluded or reflective regions, the algorithm effectively retains detailed image features..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815012 (2025)
Point Cloud Registration and Modeling Method for Gear Surfaces Based on Laser and Vision Fusion
Xingbang Zhao, Zhengminqing Li, Xiaofeng Yu, Yong Liu, and Letian Li
Aiming to address the problems of poor accuracy and low efficiency in modeling gear surfaces, as well as the lack of surface detail information in three-dimensional (3D) reconstruction models of laser point clouds, a point cloud registration and modeling method for gear surfaces based on laser and vision fusion is propAiming to address the problems of poor accuracy and low efficiency in modeling gear surfaces, as well as the lack of surface detail information in three-dimensional (3D) reconstruction models of laser point clouds, a point cloud registration and modeling method for gear surfaces based on laser and vision fusion is proposed. First, considering the high similarity between 3D features of the complete point cloud of the gear surface and the point cloud of the registration overlap area, a coarse registration method suitable for point clouds of gear surfaces is proposed. Second, aiming to address the issues of low convergence speed and poor accuracy of the iterative closest point (ICP) algorithm, improvements are made to the ICP algorithm by introducing curvature and voxel grid filtering to realize point cloud fine registration. Finally, to address the lack of surface detail information, such as color and texture, in 3D reconstruction models of laser point clouds, the checkerboard calibration method and the direct linear transform (DLT) method are combined to solve for the camera pose parameters . The laser point cloud is colored by the point cloud library (PCL) to realize the realistic modeling of gear surfaces. The experimental results indicate that compared with the traditional registration method, the proposed method reduces the root mean square error by 61% and the registration time by 53%. Unlike laser point cloud modeling, the proposed 3D reconstruction model incorporates surface texture information..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0815013 (2025)
Medical Optics and Biotechnology
Low-Dose CT Image Denoising Based on Error Modulation Module
Xiaohe Zhao, Ping Chen, and Jinxiao Pan
To address the issue of degraded image quality in low-dose X-ray computed tomography (LDCT) caused by significantly reduced ionizing radiation doses in current denoising methods, this paper proposes an enhanced diffusion model based on the U-Net network. The model introduces an error modulation module to resolve the prTo address the issue of degraded image quality in low-dose X-ray computed tomography (LDCT) caused by significantly reduced ionizing radiation doses in current denoising methods, this paper proposes an enhanced diffusion model based on the U-Net network. The model introduces an error modulation module to resolve the problem of error accumulation during sampling. Additionally, a composite loss function that combines
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0817001 (2025)
Simulation Design and Optical Signal Optimization of Blood Oxygen Sensor Based on TracePro
Sizhe Ye, Hongyi Yang, En Ma, and Fulin Lin
As an important component of wearable devices, the key parameters of the blood oxygen sensor (detection efficiency, uniformity, etc.) directly affect the performance indicators of the device. Based on the TracePro simulation platform, the simulation design of blood oxygen sensor is carried out to optimize the light proAs an important component of wearable devices, the key parameters of the blood oxygen sensor (detection efficiency, uniformity, etc.) directly affect the performance indicators of the device. Based on the TracePro simulation platform, the simulation design of blood oxygen sensor is carried out to optimize the light propagation signal. A multilayer skin tissue model conforming to Beer-Lambert's law and Henyey-Greenstein scattering function is constructed to explore the propagation law and difference of light in various skin tissues under the influence of absorption and scattering. For the blood oxygen sensor module, the spectrum and spatial light distribution of the light source and the spectral-angular response characteristics of the detector are simulated. Multi-channel module design is carried out, and the design of detector space layout, detection distance, center distance, light window, and anti-spurious light structure are optimized with luminous flux and illumination uniformity as evaluation indicators. The surfaces of constant-angle and variable-angle Fresnel lenses are constructed, the influences of surface parameters for Fresnel lenses on the spatial light distribution are compared, and the optical signal transmission before and after optimization is compared by the variable-angle Fresnel lens optimization module. Results show that the detection efficiency is increased by up to ~27% and the illumination uniformity is increased to 94.45% after optimization..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0817002 (2025)
Remote Sensing and Sensors
Multi-View Three-Dimensional Reconstruction of Weak Texture Regions Based on Simple Lidar
Tingya Liang, Xie Han, and Haoyang Li
To address the issues of holes and regional deficiencies in weakly textured areas during multi-view stereo (MVS) three-dimensional (3D) reconstruction, this paper proposes a complementary 3D reconstruction method that fuses data from MVS and lidar. First, the GeoMVSNet deep learning network is used to process multi-vieTo address the issues of holes and regional deficiencies in weakly textured areas during multi-view stereo (MVS) three-dimensional (3D) reconstruction, this paper proposes a complementary 3D reconstruction method that fuses data from MVS and lidar. First, the GeoMVSNet deep learning network is used to process multi-view images captured by a smartphone camera, resulting in MVS depth maps. Next, the smartphone camera and lidar are calibrated to compute the internal and external parameters and the coordinate system transformation matrix. Through transformations of temporal and spatial consistency, viewing angles, and scale, the sparse point cloud collected by lidar is converted to the image perspective. In addition, a depth map enhancement algorithm is proposed and applied to generate dense point cloud data from the lidar. Finally, the dense depth maps generated by lidar and the MVS depth maps are fused. Experimental results show that the reconstruction quality is significantly improved in weakly textured areas on a self-built dataset when the proposed method is used, enhancing the accuracy and completeness of 3D reconstruction. Thus, this study provides an effective solution for 3D reconstruction in weakly textured regions..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0828002 (2025)
Research on Single-Photon Sparse Point Cloud Spatio-Temporal Correlation Filtering Algorithm
Zeyu Guo, Zhen Chen, Bo Liu, Enhai Liu, and Huachuang Wang
Long-distance noncooperative target ranging echo point cloud acquired by single-photon LiDAR is sparse and contains a significant amount of noise, which renders it difficult to accurately extract effective echo and distance trajectory in real time. Therefore, a real-time extraction algorithm for single-photon LiDAR ranLong-distance noncooperative target ranging echo point cloud acquired by single-photon LiDAR is sparse and contains a significant amount of noise, which renders it difficult to accurately extract effective echo and distance trajectory in real time. Therefore, a real-time extraction algorithm for single-photon LiDAR ranging trajectory is proposed based on its temporal and spatial correlation. First, the distance-trajectory-extraction problem is converted into a curve-recognition problem based on the Hough transform, and sparse echo point cloud data is extracted from point-cloud data containing a significant amount of noise by adaptively optimizing the Hough transform. Subsequently, the extracted echo point cloud is used as the observation value of Kalman filtering to accurately estimate the target distance trajectory. In frame segments in which the target is occluded or noise exerts a significant effect, thus resulting in frame segments with missing targets owing to occlusion or severe noise, the distance and velocity information of the target in the previous frame is utilized to predict the state of the target in the current frame. The proposed algorithm processes the simulated data with a minimum signal-to-noise ratio of -9.42 dB under extreme motion conditions. Additionally, the smallest root-mean-square error of the target's distance is 0.833 m, and the lowest leakage-detection rate is 0.05. Moreover, the algorithm offers better real-time performance and can output the target distance continuously and accurately at a frame rate of 100 Hz. During the processing of the measured data, when the echo missed 885 frames continuously, the distance trajectory predicted by the algorithm deviates from the actual value by only 0.2 m. Thus, the proposed algorithm provides an effective method for the real-time accurate extraction of single-photon LiDAR ranging trajectory..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0828004 (2025)
Reviews
Dark Field Light Scattering Imaging Coupled with Surface Enhanced Raman Scattering for Analysis and Detection Application
Xinyu Lan, Guojun Weng, Xin Li, Jianjun Li... and Junwu Zhao|Show fewer author(s)
Dark field light scattering imaging is a kind of scattered light microscope imaging technique that produces a dark background by obliquely illuminating the sample with incident light. It has the characteristics of low background signal and high signal-to-noise ratio, but it is difficult to identify material compositionDark field light scattering imaging is a kind of scattered light microscope imaging technique that produces a dark background by obliquely illuminating the sample with incident light. It has the characteristics of low background signal and high signal-to-noise ratio, but it is difficult to identify material composition and internal component. Surface enhanced Raman scattering spectrum is a fingerprint spectrum of molecular vibrations with the characteristics of high sensitivity and non-destructive testing. Noble metal nanoparticles are usually used as the substrates for signal enhancement, but there is no clear standard for the selection of Raman "hot spot" area of micro-measurement, resulting in large fluctuations in Raman signals. The combination of dark field light scattering imaging and surface enhanced Raman scattering allows not only high-resolution microscopic localization of Raman "hot spot" region, but also highly sensitive detection of components in dark field imaging, and high-resolution detection of sample morphology and components can be realized simultaneously in time and space. In this review, the advantages, principles, and applications of dark field light scattering imaging coupled with surface enhanced Raman scattering are summarized, and the recent applications in biochemical molecular detection, cell detection, chemical reaction dynamic monitoring, and other aspects are introduced, which provide new ways for biomedical detections..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0800003 (2025)
Advances in Linear-Wavenumber Spectral Domain Optical Coherence Tomography
Yuxuan Li, Yanping Huang, Jingjiang Xu, Jia Qin... and Gongpu Lan|Show fewer author(s)
Spectral domain optical coherence tomography (SD-OCT) has achieved significant progress in biomedical imaging, particularly in ophthalmology. However, SD-OCT exhibits reduced signal sensitivity in deeper imaging regions compared to swept-source OCT due to the phenomenon of sensitivity roll-off. Linear-wavenumber spectrSpectral domain optical coherence tomography (SD-OCT) has achieved significant progress in biomedical imaging, particularly in ophthalmology. However, SD-OCT exhibits reduced signal sensitivity in deeper imaging regions compared to swept-source OCT due to the phenomenon of sensitivity roll-off. Linear-wavenumber spectroscopy employs an optical solution to achieve linear spectral splitting in the wavenumber domain, thereby enhancing the system's signal-to-noise ratio in the depth direction. This paper presents a comprehensive overview of the fundamental principles of the SD-OCT system, the spectroscopic theory of linear-wavenumber, the optical model of linear-wavenumber dispersion, and the application of linear-wavenumber SD-OCT in the imaging of soft tissue structures, angiography, and elastography. Although the application market for linear-wavenumber OCT remains relatively small, its ability to improve the signal-to-noise ratio and imaging speed is noteworthy. As the technology continues to advance, linear-wavenumber SD-OCT is expected to play an increasingly significant role in clinical diagnosis and biomedical research..
Laser & Optoelectronics Progress
- Publication Date: Apr. 25, 2025
- Vol. 62, Issue 8, 0800004 (2025)


© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20