 AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence

Hang Su, Yanping He, Baoli Li, Haitao Luan, Min Gu, Xinyuan Fang, "Teacher-student learning of generative adversarial network-guided diffractive neural networks for visual tracking and imaging," Adv. Photon. Nexus 3, 066010 (2024)
- Advanced Photonics Nexus
- Vol. 3, Issue 6, 066010 (2024)
Note: This section is automatically generated by AI . The website and platform operators shall not be liable for any commercial or legal consequences arising from your use of AI generated content on this website. Please be aware of this.
Abstract
Keywords
1 Introduction
Visual tracking, as a pivotal focus within the domain of computer vision, has found extensive applications across diverse fields, such as surveillance,1 autonomous driving,2 and human-computer interaction.3,4 The goal of visual tracking is to continuously estimate the position, shape, and possibly other attributes of the target over time when it moves through a scene.5,6 Therefore, visual tracking is a challenging task in computer vision, requiring robust algorithms capable of addressing complexities associated with object appearance variations, object position changes,7 dynamic environmental conditions, etc. However, large amounts of data and increasingly complex algorithms require high power consumption and significant processing time.8
Event cameras, also known as neuromorphic or dynamic vision sensors, are responsive to changes in brightness rather than capturing frames at fixed intervals compared with traditional cameras.11 The sparse data output of event cameras12 contributes to efficient data transmission and storage. Moreover, their temporal sensitivity allows for real-time responses to dynamic scenes, making them particularly suitable for applications requiring quick reactions, such as robotics and autonomous vehicles.13 In addition, the high dynamic range and robustness of motion blur enable effective performance in diverse lighting conditions and fast-paced environments.14 The sparse data output of event cameras12 contributes to efficient data transmission and less data storage. The integration of event cameras in visual tracking systems signifies a promising direction for advancing energy-efficient and high-performance visual perception technologies in various fields.15
Currently, in addressing intricate tasks, such as object detection and motion tracking, data processing technology predominantly relies on machine learning algorithms, especially convolutional neural networks (CNNs).16
Sign up for Advanced Photonics Nexus TOC. Get the latest issue of Advanced Photonics Nexus delivered right to you!Sign up now
Moreover, conventional electronic computing is constrained by slower information transmission, connectivity complexities, and energy consumption concerns. In recent developments, a novel diffractive neural network (DNN) architecture has been introduced, which can accomplish a diverse array of complex functions that can be achieved by computer-based neural networks in an all-optical way.33
In this work, we demonstrate a GAN-guided DNN, which performs visual tracking and imaging of the interested moving target. The main contributions and innovative aspects of our work are as follows: (1) Leveraging an event camera for effective moving object capture. Event cameras for effective moving object capture offer significant advantages, including high-speed, low-latency performance, efficiency, and robustness to varying lighting conditions. These attributes make the event camera a valuable tool for visual tracking tasks, particularly in dynamic or challenging environments; (2) using GANs to generate labels for DNN training; and (3) pioneering the application of DNNs in visual tracking and imaging. We further harness the generative power of the GAN-based teacher model to produce data endowed with position-tracking capabilities for the interested moving target. This generated data is subsequently employed to provide labels for the DNN-based student model, which learns to selectively image the interested moving target during training while retaining the target’s positional information. Traditionally, GANs have been employed primarily as output terminals for generating style or shape images. Here, using GANs to guide and generate labels for DNN training presents a novel and efficient solution to the problem of insufficient DNN training datasets. Notably, to the best of our knowledge, this is the first instance of utilizing DNNs in visual tracking and imaging. This approach effectively combines the strengths of both GANs and DNNs, offering a powerful and innovative methodology. Then, we apply the GAN-guided DNN to track and selectively image only a car or pedestrian in a complex scene containing a car, a pedestrian, and a tree. Our results show the successful imaging and tracking of only the interested moving target within this dynamic context. In addition, we extend our investigation to the experimental demonstration, which highlights the efficacy of GAN-guided DNN in visual tracking and imaging only the airplane in a scenario involving airplanes and missiles. Our work has also proven effective in challenging environments where traditional methods often struggle, such as in low-light conditions or complex backgrounds with inferring objects. Furthermore, the results obtained with GAN-guided DNNs, compared to those without GAN guidance, clearly show that integrating GANs significantly enhances the performance of DNNs in visual tracking and imaging.
2 Theory and Results
2.1 Overview of GAN-Guided DNNs
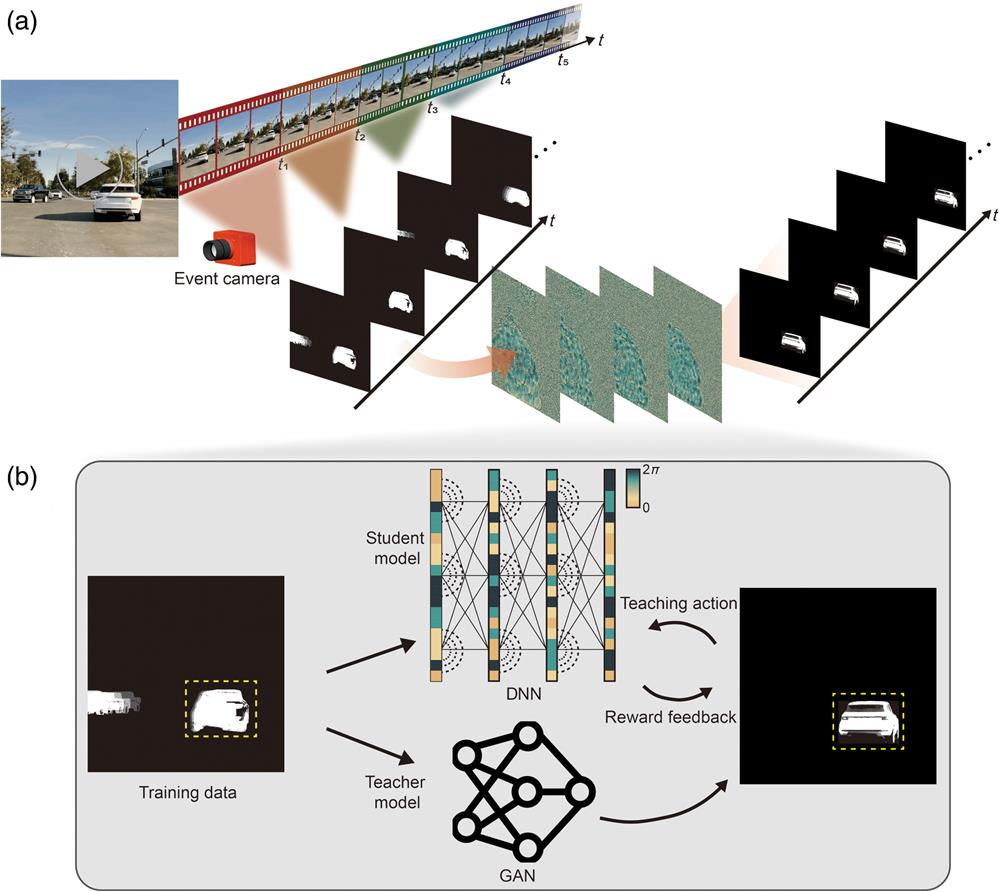
Figure 1(a) presents the entire pipeline of a GAN-guided DNN, with a time-series inputs derived from event-based video acquired by an event camera. The GAN-guided DNN is trained to selectively image the morphology and track the trajectory of the interested moving target within the input data. Here, we use the example of cars and pedestrians in a traffic scenario. As shown in Fig. 1(a), the inputs are images of moving cars (the interested target) and pedestrians, and the output of this GAN-guided DNN portrays only the selectively imaged representation of the car, enriched with positional information. This approach to selectively imaging and tracking the desired target not only enhances the efficiency of image storage but also alleviates the burden on transmission resources.
![]()
Figure 1.The overall working principle of the GAN-guided DNN. (a) GAN-guided DNN for visual tracking and imaging of the interested moving target. (b) The training process of the GAN-guided DNN.
The training process of the GAN-guided DNN is demonstrated in Fig. 1(b). We first train the GAN-based teacher model to have the capability of selectively keeping the morphology and trajectory of the interested target, which takes the car as an example in Fig. 1(b). The inputs to the GAN-based teacher model consist of time-series data capturing the movement of cars and pedestrians, obtained from event-based videos recorded by an event camera, while the sample of the GAN-based teacher model is the target car without positional information produced by numerical simulations. After training on a limited dataset, the GAN-based teacher model demonstrates the capability to generate the output target car with associated positional information for previously unseen inputs. Then, the GAN-based teacher model’s output is utilized as the labels for the subsequent training of the DNN-based student model. Incorporating corresponding time-series inputs, the trained DNN-based student model has the ability to selectively image and track the target.
2.2 Acquisition of Training Dataset and Testing Set
To obtain the training and test datasets for the GAN-guided DNN, the event-based videos with different dynamic scenarios are encoded into still images for the selective imaging task as shown in Fig. 2(a). An event-based video is a stream of events composed of numerous events, an event is a vector, which can be expressed as14,57
![]()
Figure 2.The process of training the GAN-based teacher model, which involves acquiring datasets and optimizing models. (a) The principle of input dataset acquisition using the event-based camera. (b) The architecture of the GAN-based teacher model.
Since the optical diffraction neural network cannot process the event-based video information captured by the event camera, the information should be converted into a two-dimensional gray-scale image using dimensionality compression. In our work, we encode the polarity information of the event vectors according to Eq. (2), and then the increase and decrease of pixel brightness are represented as two different gray levels on the grayscale image:
By stacking all the events over a period of time, we obtain an image that contains information about the motion of the target object over that period of time, which can be represented as an image:
Based on the previous core steps of acquiring the training and test datasets, when an event camera is used to capture the dynamic action, a noise filter is set on the appropriate software for denoising, and then the event-based video is converted into an image using the stacking-based on-time method. More details about the event camera can be found in Note 1 in the Supplementary Material.
Using this approach, we then obtained the dataset for training and testing the GAN-guided DNN. A total of three scenarios are captured for training and simulation testing of our GAN-guided DNN on the computer, including 600 images for training and 120 images for testing. In addition, there is another scenario used to test our DNN through experimental light paths, which consists of 480 and 120 images for training and testing sets, respectively. All images are
2.3 Principle and Architecture of the GAN-Based Teacher Model
Position information plays a vital role in the domain of visual tracking. However, conventional neural networks applied for target imaging frequently neglect such crucial positional details, which mainly arises from the inherent difficulty associated with obtaining precise positioning information when imaging a target with an uncertain location. Hence, owing to the absence of precise location information, conventional DNNs are trained without incorporating target labels that contain positional information. In our work, a GAN-based teacher model is used to generate the target labels with positional information. Figure 2(b) shows the training process of the GAN-based teacher model framework, which contains two fundamental components, a generator and a discriminator. The GAN-based teacher model constructs a mapping function between two domains by learning the feature information from two sets of images and attempts to convert one set of images into another using a generator.62
The architecture of the generator implemented in the GAN-based teacher model consists of inputs and outputs with multiple convolutional layers. To reduce the size of the input information and extract shallow low-level features, downsampling is performed on the input images. The presence of the nonlinear activation function ReLU causes irreversibility in both input and output, resulting in information loss in the model. Moreover, the deeper layers of the network use an increased number of ReLU functions, leading to further information loss. This makes it difficult to preserve the shallow features with the propagation of the antecedent terms. To address this issue, a residual block is introduced in the intermediate convolutional layers. This block is directly incorporated into the original network with a cross-layer connection to preserve information integrity and simplify the learning objective and difficulty. The convolution is then used to up-sample and recover the size of the input information while extracting deeper advanced features. The final output image is then derived from this process.
The discriminator model in the GAN-based teacher model aims to differentiate between authentic and generated images. The generated images are inputted into the discriminator, undergoing compression into a discriminant matrix through multiple convolutional layers. The discriminant matrix determines the quality of the generator’s image, aiding the optimization process (see Sec. 4 for details). Through iterative training, the generator refines its output to become increasingly indistinguishable from real data, while the discriminator enhances its ability to make accurate distinctions.
2.4 Imaging and Tracking Interested Moving Targets Using GAN-Guided DNNs
We first present a simulated numerical demonstration of the GAN-guided DNN within scenarios involving a pedestrian and a car in typical encounters in traffic, with a specific emphasis on car imaging and tracking. As illustrated in Fig. 3(b), a four-layer DNN-based student model with phase-only modulation is trained, which is learned as a result of this data-driven training approach. The phase modulation range for each diffractive layer spans from 0 to
![]()
Figure 3.Simulation results of GAN-guided DNN. (a) Examples of training results for the visual tracking and imaging of the target car. (b) The phase profiles of diffractive layers after deep learning-based optimization. (c) The PSNR and SSIM values with different input images.
Following training, the GAN-guided DNN model undergoes numerical testing utilizing grayscale images involving a pedestrian and a car, which are represented in amplitude within the range of 0 to 1. Figure 3(a) presents a subset of the examples utilized for testing, which includes inputs, labels, and outputs. The output images are depicted as light-intensity maps following normalization. It is crucial to highlight that the deficiency of information in images due to rapid motion can be effectively addressed through the implementation of the GAN-guided DNN. Figure 3(c) illustrates the quantitative evaluation results of the GAN-guided DNN model, wherein structural similarity index (SSIM) values and peak signal-to-noise ratio (PSNR) values are computed through a comparison between the outputs and the labels across 40 frame. The SSIM values exhibit a fluctuation hovering around 0.9, all of which surpass the threshold of 85. So the output images can be considered very similar to the labels from the perspective of structural similarity (closer to human eye recognition), which includes brightness, contrast, and structure. Meanwhile, PSNR values display a similar pattern of fluctuation, with an average value circling 26, which underscores the excellence in signal-to-noise ratio, affirming the quality and precision of the GAN-guided DNN output. The resultant output showcases the successful application of the GAN-guided DNN in isolating and tracking the designated moving car, offering a streamlined and resource-efficient solution for processing event-based video data.
To demonstrate the stability of our model, we evaluated its performance in a more complex scenario involving an interfering car with the same speed, profile, and size as the target car. As shown in Fig. S1 in the Supplementary Material, the results confirm that our method remains effective under these challenging conditions. Furthermore, we also evaluate our model under varying lighting conditions to assess its robustness in more general scenarios. As demonstrated in Fig. S2 in the Supplementary Material, the model continues to deliver excellent performance even in difficult environments, enhancing its relevance to real-world applications.
2.5 Quantification of the Performance of the GAN-Guided DNN with Different Numbers of Layers
To quantitatively evaluate the performance of different numbers of layers on the accuracy of imaging and tracking the interested moving target, we systematically trained three GAN-guided DNN models with different layer numbers:
![]()
Figure 4.The GAN-guided DNN trained and tested with different numbers of diffractive layers. (a) The performance of the GAN-guided DNN with different numbers of diffractive layers (
Then, we conducted a comprehensive comparison of the three models, examining not only their visualizations but also considering metrics, such as SSIM values and PSNR values, for the outputs. In Fig. 4(b), we can see that SSIM values for the three models are all above 0.9, which signifies a notable level of structural similarity between the compared images. The PSNR values are all larger than 16 dB, which means the quality of output images is very similar. Despite encountering some fluctuations, it is imperative to emphasize that the overall outcomes remain favorable. Our analysis underscores that the two-layer GAN-guided DNN exhibits comparatively lower accuracy in both imaging and tracking. Importantly, our results elucidate a notable enhancement in the performance of the GAN-guided DNN with a substantial increase in the number of diffractive layers.
2.6 Experimental Demonstration
We further experimentally demonstrated the feasibility of the GAN-guided DNN with the experimental setup shown in Fig. 5(a). The incident continuous wave at a wavelength of 632.8 nm is generated by a He-Ne laser (CW, HNL210L, Thorlabs) with a power output of 14.4 mW. A half-wave plate (HWP) and a polarization beam splitter (PBS) are integrated to continuously adjust both the power and polarization of the laser beam. The laser beam is then spatially magnified using the 4f system, comprising Lens 1 (OLD1430-T2M, JCOPTIX, China) with a focal length of 30 mm and Lens 2 (OLD2474-T2M, JCOPTIX, China) with a focal length of 500 mm. Concurrently, a
![]()
Figure 5.Experimental demonstration of the visual tracking using a GAN-guided DNN. (a) Schematic diagram of the experimental setup and phase used in the experiment (layer 1 and layer 2 are loaded on SLM 1 and SLM 2, respectively). HWP, half-wave plate; PBS, polarization beam splitter; QWP, quarter-wave plate; BS, beam splitter; SLM, spatial light modulator. (b) Simulation and experimental results of visual tracking and imaging of the target airplane in a scenario involving airplanes and missiles. (c) The SSIM and PSNR values of the simulation and experimental results with different input images.
For the experimental validation, we constructed a GAN-guided DNN with two diffractive layers denoted as layer 1 and layer 2, as shown in Fig. 5(b). Each layer is comprised of
To test the GAN-guided DNN, 40 different images containing airplanes and missiles are used as the inputs to the network. A comparison of the obtained experimental results with the simulation results is presented in Fig. 5(c). The results show that the experimental measurements are in good agreement with the numerical simulations. The GAN-guided DNN faithfully represents the target (airplane) in the corresponding position while effectively inhibiting the formation of another object (missile) in precise agreement with our numerical simulations. Figure 5(d) shows the SSIM and PSNR of the experimental test results versus the simulated results, which reveals that the results of visual tracking and imaging of the interested moving target in the actual test exhibit a slightly lower performance than expected. Nonetheless, the results still demonstrate a commendable capability to effectively execute tasks of visual tracking and imaging of the interested moving target with a high level of quality.
3 Discussion and Conclusion
We have demonstrated a GAN-guided DNN that performs real-time visual tracking and imaging of the interested moving target. There are three key components in our method: (i) the event camera, acclaimed for its remarkable responsiveness to changes in brightness, facilitates the real-time, energy-efficient, and high-performance capture of dynamic scenes. (ii) The GAN-based teacher model, operating within an unsupervised learning paradigm, enables the generation of labels with position-tracking capability of the interested moving target for DNN-based student model. To demonstrate the necessity of the GAN-based teacher model, we present a comparative analysis between the GAN-guided DNN and a DNN without GAN guidance in the Supplementary Material (see Note 5 and Fig. S4 in the Supplementary Material). (iii) The DNN-based student model, computing at the speed of light, performs real-time visual tracking and imaging of the interested moving target with low energy consumption. Our work demonstrated exceptional performance in tracking fast-moving objects, particularly due to the integration of the event camera’s high temporal resolution. The asynchronous data provided by the event camera allowed the model to maintain accurate tracking even when traditional frame-based methods struggled with motion blur or missed detections. Our method also performed robustly in low-light conditions, where traditional cameras typically suffer from noise and poor contrast. The event camera’s resilience to varying lighting conditions contributed to stable tracking performance, which indicates the potential for real-world applications where lighting conditions are unpredictable. When tested in environments with different complex backgrounds, our methods showed improved generalization capabilities. However, it may still exhibit overfitting when exposed to environments that are significantly different from those in the training set. In addition, the model may struggle to differentiate between the target and similar objects, leading to potential tracking inaccuracies. To address these challenges, future work could explore domain adaptation or transfer learning techniques to improve the model’s robustness across diverse and unseen environments. Techniques such as contrastive learning or data augmentation could further improve the model’s ability to recognize and differentiate between similar objects. Incorporating these approaches would help mitigate the risk of overfitting and enhance the model’s ability to distinguish between similar objects, ultimately improving its performance in complex and dynamic real-world applications.
Notably, compared to traditional manual methods for obtaining training labels, GANs offer significant advantages in terms of speed, convenience, and improved modeling of data distribution, resulting in sharper and clearer images. Unlike other image generation models, GANs do not require Markov chains for repeated sampling, do not necessitate inference during the learning process, and avoid complex variational lower bounds, thereby sidestepping the challenges of probabilistic approximation computation. In addition, the interplay between the generator and discriminator in GANs is more straightforward to integrate with other networks. The comparison of GAN-guided DNNs and existing visual tracking and imaging solutions has been discussed in Note 6 in the Supplementary Material. Our GAN-guided DNN has been successfully applied to diverse autonomous driving scenarios, which demonstrates an excellent performance with SSIM values of greater than 0.85 and PSNR values of over 16. Furthermore, a notable enhancement has been achieved when we increased the number of diffractive layers. We also apply the GAN-guided DNN for visual tracking and imaging of the ultrahigh-speed moving airplane. Both the simulation and experimental results indicate that our method has good performance in visual tracking and imaging of high-speed moving objects. Moreover, from the results we can see that the lack of information in images caused by high moving speed can be compensated by the GAN-guided DNN.
In summary, we have proposed a GAN-guided DNN for visual tracking and imaging of the dynamic target with high energy efficiency, low power consumption, and ultrahigh speed. The GAN-guided DNN eliminates unnecessary background information and enhances information utilization while reducing information storage costs. It is worth noting that the diffractive layers can be fabricated by two-photon polymerization technology and then assembled together to form a micrometer-scale optical chip. The optical chip operates without consuming any power other than the illumination source, which has the advantages of the speed of light, almost no power consumption, reduced weight and size, as well as robustness to diverse lighting conditions. In addition, if the DNN is used instead of the event camera to collect electrical data, resulting in all-optical computing in memory, it will greatly reduce energy consumption and significantly improve computing efficiency, making it highly applicable in fields such as artificial intelligence and autonomous driving.67 Our method is anticipated to have a significant impact on various industries, offering a versatile and efficient solution for a wide range of optical data processing applications.
4 Methods
4.1 Numerical Forward Model of the GAN-Guided DNN
The GAN-guided DNN used for visual tracking and imaging consists of
The forward propagation model of the GAN-guided DNN is modeled by alternating applying the operations of free-space propagation in Eq. (4) and phase modulation of the diffraction layer in Eq. (5). For a given input optical field, the complex amplitude field of the output result is obtained in the output plane of the diffraction network.
4.2 Digital Implementation and Training Details
In order to train the network to achieve visual tracking and imaging of the interested moving target, the parameters of the GAN-guided DNN are optimized by minimizing the loss function. The loss function is MAE, which is calculated using the intensities of the labels and network outputs,49
For the experimented scenarios in Fig. 5, we present the GAN-guided DNN with two diffractive layers to perform the task of visual tracking and imaging of the fast-moving airplane. Each diffraction layer contains
4.3 Training Process of the GAN-Based Teacher Model
For GAN-based teacher model training, our goal is to learn the mapping function of the domains
Ideally, the GAN-based teacher model should learn cycle-consistent transformation functions
In practice, however, these transformations do achieve the goal. It is important to note that
The function of the complete GAN-based teacher model loss used to train the network is defined as the sum of the two GAN-based teacher model losses and the cycle consistency loss. Therefore, the loss function of our model can be expressed as
Our goal is to minimize the difference between real and generated samples, while maximizing the ability of the discriminators
Further details on the construction and training of the GAN are provided in Note 7 in the Supplementary Material.
Hang Su is currently a PhD student in the School of Artificial Intelligence Science and Technology at the University of Shanghai for Science and Technology. He received his BS degree in optical information science and technology from the East China university of Science and Technology in 2021. His current research focuses on orbital angular momentum holography and optical imaging.
Yanping He is currently an assistant research fellow in the School of Artificial Intelligence Science and Technology at the University of Shanghai for Science and Technology. She received her PhD from The Chinese University of Hong Kong. Her research focuses on optical imaging, image flow cytometry, and optical diffractive neural networks.
Xinyuan Fang is a professor at the University of Shanghai for Science and Technology. His research areas include multi-dimensional light field manipulation, optical neural networks, and holography. Until now, he has published more than 30 peer-reviewed papers as the co-first/co-corresponding author, such as Science, Nature Photon., Nature Nanotech., Light Sci. Appl., Adv. Photon., and Nano Lett. He is the recipient of the Excellent Young Scientists Fund of NSFC.
Biographies of the other authors are not available.
References
[5] X. Chen et al. Transformer tracking, 8126-8135(2021).
[12] N. Messikommer et al. Event-based asynchronous sparse convolutional networks, 415-431(2020).
[14] L. Wang et al. Event-based high dynamic range image and very high frame rate video generation using conditional generative adversarial networks, 10081-10090(2019).
[17] M. Gehrig, D. Scaramuzza. Recurrent vision transformers for object detection with event cameras, 13884-13893(2023).
[18] X. Wang et al. Visevent: reliable object tracking via collaboration of frame and event flows. IEEE Trans. Cybern.(2023).
[22] J. T. Springenberg. Unsupervised and semi-supervised learning with categorical generative adversarial networks. arXiv:1511.06390(2015).
[24] T. Karras et al. A style-based generator architecture for generative adversarial networks, 4401-4410(2019).
[25] T. Karras et al. Alias-free generative adversarial networks. Adv. Neural Inform. Process. Syst., 34, 852-863(2021).
[27] W. Xu et al. DRB-GAN: a dynamic resblock generative adversarial network for artistic style transfer, 6383-6392(2021).
[32] W. Peebles et al. GAN-supervised dense visual alignment, 13470-13481(2022).
[44] Y. Li et al. Analysis of diffractive neural networks for seeing through random diffusers. IEEE J. Sel. Top. Quantum Electron., 29, 1-17(2022).
[57] J. Chen et al. Dynamic graph CNN for event-camera based gesture recognition, 1-5(2020).
[58] Y. Deng et al. A voxel graph CNN for object classification with event cameras, 1172-1181(2022).
[59] P. Wzorek, T. Kryjak. Traffic sign detection with event cameras and DCNN, 86-91(2022).
[62] I. Goodfellow et al. Generative adversarial nets. Adv. Neural Inform. Process. Sys., 27(2014).
[64] D. Torbunov et al. UVCGAN: UNet vision transformer cycle-consistent GAN for unpaired image-to-image translation, 702-712(2023).
[65] J.-Y. Zhu et al. Unpaired image-to-image translation using cycle-consistent adversarial networks, 2223-2232(2017).
[66] Y. Yuan et al. Unsupervised image super-resolution using cycle-in-cycle generative adversarial networks, 701-710(2018).


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20