 AI Video Guide
AI Video Guide  AI Picture Guide
AI Picture Guide AI One Sentence
AI One Sentence

Yan Li, Tai-Kang Tian, Meng-Yu Zhuang, Yu-Ting Sun. De-biased knowledge distillation framework based on knowledge infusion and label de-biasing techniques[J]. Journal of Electronic Science and Technology, 2024, 22(3): 100278
- Journal of Electronic Science and Technology
- Vol. 22, Issue 3, 100278 (2024)
Note: This section is automatically generated by AI . The website and platform operators shall not be liable for any commercial or legal consequences arising from your use of AI generated content on this website. Please be aware of this.
Abstract
1 Introduction
In the field of deep learning, with the increasing complexity of model structures and the increase in training data volume, significant breakthroughs have been achieved in model performance [1–3]. Although this progress is encouraging, it also faces challenges such as overfitting, high consumption of computing resources, and high sensitivity of models to different data distributions. These issues limit the application and deployment of deep learning models in resource-constrained environments [4–6]. In order to improve the availability and performance of models in resource-constrained environments and enhance their generalization ability, researchers have proposed many model compression methods [7–10]. Hinton et al. proposed the technology of knowledge distillation among them [11]. This technology utilizes the rich knowledge contained in a complex and high-performance teacher model to guide the training process of a lightweight student model, enabling the student model to achieve performance levels similar to the teacher model. Knowledge distillation technology can be mainly divided into two types: One is response-based knowledge distillation, which focuses on utilizing the logits distribution output by the teacher model; another approach is feature-based knowledge distillation, which focuses on utilizing information from the middle layer of the teacher model [12].
At first, knowledge distillation technology mainly optimized the performance of student models by maximizing the distribution similarity between the logits predicted by teacher and student models [13]. With the passage of time, the emergence of feature-based knowledge distillation has gradually shifted the focus of research [14], because this method has shown more significant advantages in improving model performance compared with response-based knowledge distillation [15–17]. However, feature distillation faces additional computational burdens, including complex model structures and computational operations, which often exceed the acceptable range of practical applications [18]. At the same time, although response-based knowledge distillation may not perform as well as feature distillation in terms of performance, it requires much less computing resources and storage space, providing convenience for the deployment of student models. More importantly, it relies on high-dimensional semantic features in the teacher model, which theoretically should include richer knowledge. Therefore, intuitively, response-based knowledge distillation can achieve more effective knowledge transfer.
We believe that the bias of the teacher model itself is a key factor limiting the effectiveness of response-based knowledge distillation [19]. In view of this, we propose a de-biased knowledge distillation (DeBKD) framework suitable for binary classification tasks. This framework integrates knowledge infusion and label de-biasing techniques based on the basic principles of knowledge distillation, aiming to simultaneously reduce the teacher model bias contained in soft labels and improve the performance of student models. By using label de-biasing techniques, the student model is given more freedom to explore the correlation between categories, effectively reducing the limitation of original soft label biases on the performance of the student model. And by using knowledge infusion techniques to correct misjudged samples from the teacher model, the student model becomes less prone to errors, thus accelerating the convergence of the model. DeBKD not only enables the student model to inherit the high performance of the teacher model, but also reduces the potential bias impact in the data, thereby enabling the model better generalization ability and fairness when dealing with diverse datasets. Through a series of experiments on real datasets, we have validated the effectiveness of the DeBKD framework on model compression. The main contributions of this study are as follows:
1) This article proposes a distillation framework called DeBKD to address the potential teacher model bias issue in response-based knowledge distillation. This framework effectively utilizes the knowledge of teacher models and provides students with sufficient learning freedom to achieve better performance, achieving efficient and convenient model compression.
2) This article proposes a flexible deviation removal technique called knowledge infusion. It effectively reduces the negative impact of teacher model prediction biases on student model performance and demonstrates the universality of unbiased techniques in achieving efficient model compression.
3) We conducted a series of comprehensive experiments to determine the effectiveness of the DeBKD framework. The results show that the DeBKD framework’s model compression ability in binary classification tasks exceeds that of traditional response-based knowledge distillation and feature-based knowledge distillation.
2 Related work
2.1 Research on biases in deep learning
In the fields of machine learning and deep learning, biases in data, algorithms, or models can lead to a decline in the generalization performance of models. To address bias issues, Xu et al. [20] proposed a knowledge distillation method based on uncertainty constraints, aimed at de-biasing the conversion rate (CVR) estimation model by extracting knowledge from non-clicked samples. This method achieves an unbiased estimation across the entire space by generating reliable pseudo labels, but its ultimate effectiveness depends on the quality of these pseudo labels. Li et al. [21] highlighted that biased data could lead to incorrect gradient updates and model overfitting, and they developed a de-biasing generative framework for graph data to effectively mitigate the impact of biased data. This framework demonstrates good performance in handling the bias in graph data, but there is still room for the improvement in terms of computational complexity and scalability. Cao et al. [22] investigated the issue of the spectral bias observed in deep learning, where neural networks tend to learn functions of lower complexity. Their experiments showed that over-parameterized neural networks are more inclined to learn lower-order spherical harmonic functions. While this study reveals learning preferences of neural networks, further exploration is needed on how to effectively guide networks to learn more complex functions. In addition, de-biasing techniques have also been widely studied in areas such as pre-trained language models (PLMs) [23], recommendation systems [24], meta-learning [25], and natural language processing [26]. Current research on de-biasing techniques primarily focuses on mitigating data imbalance or unfairness during the data preprocessing stage, with little attention given to biases arising during model interaction processes. This paper innovatively introduces the concept of de-biasing domains, effectively reducing biases in the information transfer process between models, thereby enhancing the effectiveness and efficiency of information interaction.
2.2 Knowledge distillation
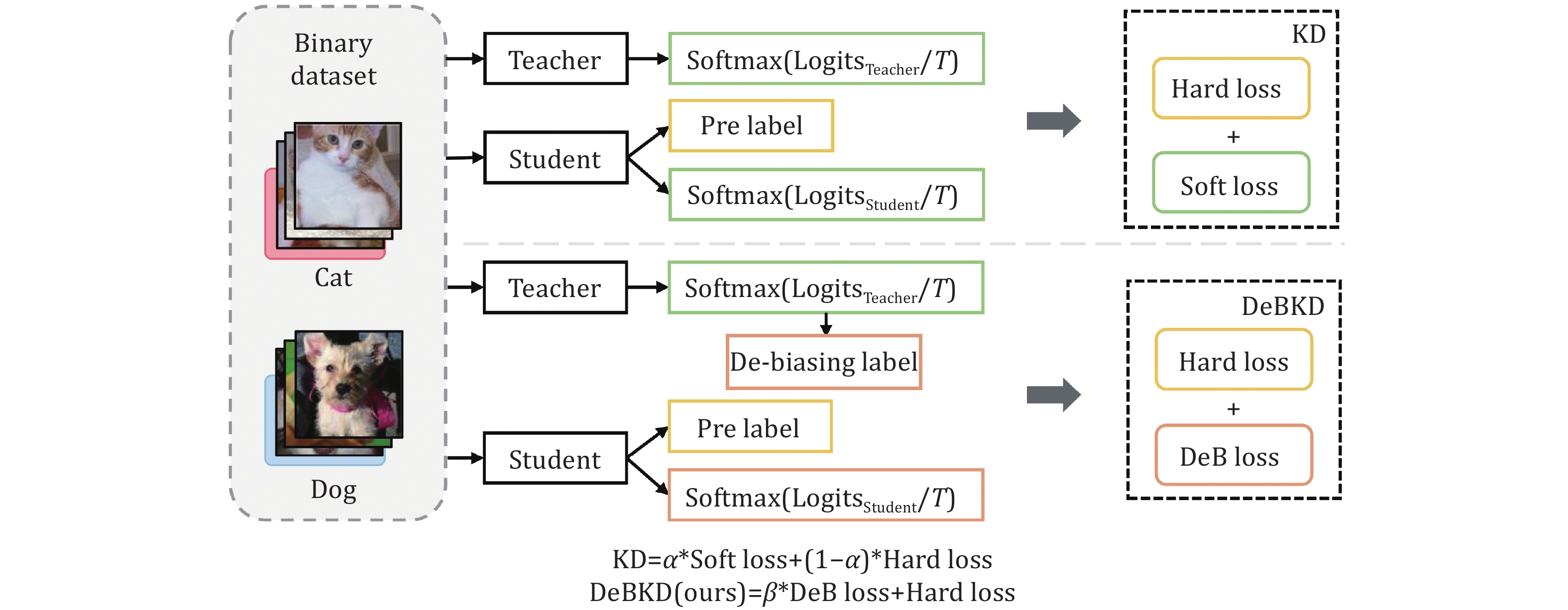
The concept of knowledge distillation was first formally introduced by Hinton et al. [11], with the aim of transferring a large and complex teacher model to a small and simple student model through the use of soft labels, thereby improving performance while compressing the model. Current research on knowledge distillation mainly focuses on the efficient deployment of deep learning models in resource-constrained environments. Heo et al. [27] proposed a new feature distillation method based on feature knowledge, which enhances the student’s learning ability of the teacher’s deep information by directly transferring feature layer information, although it does not effectively address model heterogeneity issues. Park et al. [28] emphasized the relationships between data samples and utilized these relationships to achieve knowledge distillation, further improving the model’s ability to capture inter-sample relationships. Zhao et al. [29] decoupled knowledge distillation into two parts: Target class knowledge distillation (TCKD) and non-target knowledge distillation (NCKD), verifying the effectiveness of NCKD and the coupling loss of the original model. Although knowledge distillation has been widely used in deep learning as a mainstream technique for model compression and acceleration, bias issues limit its application in the fields with higher demands for model accuracy and fairness, such as healthcare, finance, and autonomous driving. Currently, there is little research on addressing the bias during the knowledge distillation process. Zhou et al. [30] studied the impact of regularized samples on knowledge distillation to tackle bias issues, indicating that further improvements in soft labels are needed to assist neural networks in de-biasing. Based on this approach, this paper utilizes label de-biasing and knowledge infusion techniques to eliminate the bias in the soft labels of teacher models and further proposes the DeBKD loss to help the student model avoid the influence of the bias present in the teacher model. In Fig. 1, we demonstrate the difference between DeBKD and traditional response-based knowledge distillation in terms of optimization objectives. Unlike knowledge distillation, where the distillation process simply combines hard and soft labels for joint supervision, we apply label de-biasing and knowledge infusion to the soft labels. We redefine the loss function as a weighted sum of the hard loss and de-biased label loss, where
![]()
Figure 1.Illustration of the classical knowledge distillation (KD) and our de-biased knowledge distillation (DeBKD).
3 Methodology
In this section, we will first review the traditional knowledge distillation method, followed by an introduction to the DeBKD approach that we have developed.
3.1 Background
As a primary model compression technique, knowledge distillation has been widely employed in various vision tasks. This approach typically involves a two-step process. First, a complex and high-performing teacher model, referred to as Teacher, is pre-trained. Subsequently, a lightweight student network, referred to as Student, is trained under the joint supervision of both the real labels and the soft labels or intermediate layer information output by the teacher model. Through the knowledge distillation process, the student model is able to learn and acquire the knowledge of the teacher model, facilitating its eventual deployment. For a classification dataset with k classes, given an input vector
where T represents a temperature parameter that regulates the smoothness of the distribution. A lower T value sharpens the distribution, magnifying the distinctions between different distributions and directing the distillation process to concentrate primarily on the most probable class in the output logits of the teacher model. Conversely, a higher T value flattens the distribution, narrowing the discrepancies between the two models and enabling the distillation to encompass the full range of the logits distribution.
The cross-entropy loss function is employed to minimize the discrepancies between the soft label probabilities of the student and teacher models, as well as the deviations from the true labels. This approach is instrumental in enhancing the performance of the lightweight student model, ensuring it achieves optimal effectiveness:
where the cross-entropy between the output of the student model’s logits
The cross-entropy between the softmax output of the student model under T = 1 and the true labels constitutes the second part of the distillation loss:
3.2 De-biased knowledge distillation
The knowledge distillation method, which employs the logits distribution output by the teacher model as the fitting target during training, transfers not only the teacher’s expertise to the student model during model compression but also its inherent biases. These biases could potentially restrict the student model’s learning capacity, as the student may inherit and even amplify these biases. To mitigate the impact of biases introduced by the teacher model, it is suggested to utilize de-biased labels instead of soft labels as the fitting target during training. Fig. 2 illustrates the workflow of the DeBKD framework. In this framework, de-biasing focuses on correcting misclassifications and inherent biases in the teacher model. For misclassifications, we extract soft labels for incorrectly categorized instances from a teacher model pre-trained on a binary classification dataset. We then apply knowledge infusion techniques, using the average distribution of the model’s correct predictions as a corrective measure. All soft labels are subsequently adjusted with a label de-biasing technique to address inherent biases. These de-biased labels, along with hard labels, jointly supervise the training of the student model.
![]()
Figure 2.Workflow of the proposed de-biased knowledge distillation framework.
3.2.1 Knowledge infusion
The biases present in the teacher model manifest through its misclassifications, which negatively impact the convergence and robustness of the student model. This issue arises from the discrepancy between the teacher’s incorrect predictions and the true labels. When the student model attempts to learn from these misclassified soft labels, it encounters a dilemma: Aligning with the true labels increases the soft label loss, whereas overfitting to the misclassified soft labels raises the true label loss. This conflict can significantly hinder the student model’s convergence speed and overall performance.
In Fig. 3, we illustrate the process of knowledge infusion. To mitigate the negative impact of biases introduced by the teacher model’s misclassifications on the student model’s learning process, the technique of knowledge infusion has been proposed. Knowledge infusion aims to optimize the student model’s training process by adjusting the soft label distributions of the teacher model’s misclassifications. Instead of directly using the logits distributions of these misclassifications, knowledge infusion extracts the mean logits distribution
![]()
Figure 3.Process of knowledge infusion.
3.2.2 Label de-biasing
To mitigate the biases carried in the soft labels and give the student model more freedom to explore inter-class relationships based on the teacher’s guidance, we can uniformly divide the output class probability distribution space of the teacher model into n de-biased regions
3.2.3 De-biased knowledge distillation loss
The knowledge distillation loss based on responses aims to minimize the difference between the logits distributions of the student’s output and those of the teacher’s output, as well as the difference between the student model’s predictions and the true labels. Considering that the biases in the teacher model are primarily introduced by the soft label loss, de-biased labels are introduced to replace the soft labels as the new optimization target. The goal is to enable the student model to fit the teacher model’s output within the defined de-biased regions. The de-biased label loss is defined as
To achieve better performance for the student model, the true labels are also introduced to jointly supervise the training of the student model. The de-biased distillation loss is defined as
where
4 Experiment
In this section, the proposed DeBKD framework is applied to residual neural networks with different numbers of layers to evaluate the distillation effectiveness of the framework. As an improved response-based knowledge distillation framework, we compare it with traditional response-based knowledge distillation and feature-based knowledge distillation. All results are reported as the average of three trials.
4.1 Datasets
Three publicly available binary image datasets from Kaggle are selected in this paper: Dog and Cat (D&C), which consists of
To unify the input format and optimize the model training efficiency, the following preprocessing steps are performed on all datasets: Firstly, the image size is uniformly adjusted to 32×32 pixels to ensure consistent processing of data in the model. Then, normalization is applied to scale the pixel values of each channel of the images to the range [0, 1] and further adjusted to a distribution with a mean of 0.5 and a standard deviation of 0.5, aiming to mitigate the effects of illumination variations and color biases during model training. Among the images, 70% are used for the training set, 10% for the validation set, and 20% for the test set.
4.2 Evaluation metrics
Commonly used metrics to evaluate the classification performance of network models, including accuracy (Acc), precision (Pre), and recall (Rec), are often applied in binary classification tasks. Their calculation formulas are shown in (7)–(9):
where TP, TN, FP, and FN represent the numbers of true positives, true negatives, false positives, and false negatives, respectively.
By integrating these three metrics, we assess the model’s performance from multiple angles—its overall effectiveness, accuracy of positive predictions, and coverage of positive samples. This comprehensive evaluation offers crucial insights into the model’s strengths and areas for the improvement, guiding further optimization and applications.
4.3 Overall comparison
Using a 50-layer deep residual neural network as the teacher model, experiments were conducted on 18-layer and 8-layer deep residual neural network student models employing response-based knowledge distillation (KD-18 & KD-8 in Table 1), feature-based knowledge distillation (FKD-18 & FKD-8 in Table 1), and the proposed de-biased knowledge distillation (DeBKD-18 & DeBKD-8 in Table 1). In these experiments, the outputs of the first, third, and last residual blocks of the teacher model were selected as feature maps for the student model to learn and fit. Through evaluation on three real-world datasets, the performance of DeBKD in model compression was compared with other knowledge distillation methods, including classification accuracy, precision, and recall.
| Method | D&C | C&H | C&B | ||||||||
| Acc (%) | Pre (%) | Rec (%) | Acc (%) | Pre (%) | Rec (%) | Acc (%) | Pre (%) | Rec (%) | |||
| Teacher | 84.98 | 84.22 | 84.22 | 90.03 | 90.13 | 90.38 | 93.23 | 93.40 | 93.26 | ||
| KD-18 | 82.64 | 82.64 | 83.33 | 88.09 | 89.58 | 97.32 | 91.32 | 90.84 | 91.35 | ||
| KD-8 | 79.54 | 80.09 | 79.54 | 83.78 | 84.68 | 83.07 | 82.94 | 86.93 | 82.77 | ||
| FKD-18 | 82.98 | 82.88 | 83.05 | 88.74 | 87.67 | 91.79 | 91.87 | 91.65 | |||
| FKD-8 | 79.44 | 79.47 | 79.36 | 86.42 | 86.56 | 86.36 | 84.21 | 84.33 | 84.13 | ||
| 89.85 | |||||||||||
| DeBKD-8 | 80.80 | 80.81 | 80.80 | 86.73 | 87.48 | 86.15 | 89.06 | 90.23 | 88.97 | ||
Table 1. Comparison of distillation effects across different datasets.
The experimental results in Table 1 demonstrate that DeBKD outperforms traditional response-based knowledge distillation methods in all evaluation metrics. When applied to the 18-layer residual neural network, DeBKD achieved accuracy improvements of 0.48%, 1.69%, and 2.02% over response-based knowledge distillation on the three datasets, respectively. The accuracy gains were even more significant on the 8-layer network, with the increases of 1.26%, 2.95%, and 6.12%, respectively. This achievement proves that DeBKD, through knowledge infusion and label de-biasing techniques, achieves more effective knowledge transfer, enabling the student model to learn and utilize knowledge better, surpassing the learning capacity limitations of traditional methods, and thereby achieving superior performance.
Moreover, DeBKD outperforms feature-based knowledge distillation methods in almost all metrics. Although previous studies often indicate that feature-based knowledge distillation outperforms response-based knowledge distillation in most cases, the application of DeBKD demonstrates that response-based knowledge distillation can surpass feature-based methods when the student model can more effectively utilize deep semantic logits distribution information. Specifically, the accuracy improvements on the 18-layer network were 0.14%, 0.96%, and 1.55%, while on the 8-layer network, the accuracy gains were 1.36%, 0.31%, and 3.85%. These results highlight the potential of DeBKD in promoting model compression and enhancing learning efficiency.
4.4 Parameter sensitivity analysis
4.4.1 Impact of different learning freedom
Learning freedom (
The impact of different learning freedom on the classification accuracy of 18-layer and 8-layer deep residual neural network models (DeBKD-8 & DeBKD-18 in Table 2) was investigated across three datasets, and the results are presented in Table 2. It was observed that the performance declined steadily when the learning freedom was less than or larger than 1/12. This trend aligns with the initial hypothesis that the student model suffers from the biases of the teacher model when learning freedom is too low, and fails to effectively utilize the information transmitted by the teacher model when learning freedom is too high. The highest accuracy was achieved when learning freedom was set to 1/12, which has been established as the default setting for the DeBKD framework.
| Learning freedom | D&C | C&H | C&B | |||||
| DeBKD-8 | DeBKD-18 | DeBKD-8 | DeBKD-18 | DeBKD-8 | DeBKD-18 | |||
| 1/8 | 78.98 | 79.42 | 70.62 | 85.21 | 82.81 | 88.54 | ||
| 1/10 | 79.48 | 82.08 | 83.71 | 86.73 | 86.79 | 91.02 | ||
| 84.38 | ||||||||
| 1/14 | 79.64 | 80.36 | 85.81 | 85.47 | 91.15 | |||
| 1/16 | 77.40 | 78.48 | 85.05 | 84.29 | 83.85 | 91.15 | ||
Table 2. Impact of different learning freedom on the classification accuracy.
4.4.2 Impact of different mixing weight
In the DeBKD framework, one of the significant improvements to the traditional distillation process is the introduction of the de-biased label loss, which replaces the standard soft label loss. The design of this de-biased label loss aims to mitigate the influence of potential biases from the teacher model on the student model, while enhancing the student model’s autonomy in identifying complex relationships between categories. The introduction of the mixing weight (
During experimental observations on three different datasets, we noticed that when the mixing weight was maintained within the range of 0.1 to 0.3, the model exhibited stability in performance. This indicates that within this range, the mixture of de-biased label loss and hard label loss can effectively promote the student model’s learning without introducing additional performance losses. This parameter setting demonstrates its generalizability and robustness under certain environments.
However, once
4.5 Ablation study
Within the DeBKD framework, the knowledge infusion technique serves as a flexible enhancement tool aimed at mitigating biases in the misclassified class logits distribution of the teacher model and reducing the learning difficulty for the student model. This technique optimizes the transfer of misclassified information, enabling the student model to learn and understand complex data patterns more effectively, thereby enhancing its generalization capabilities without sacrificing model accuracy.
To validate the effectiveness of the knowledge infusion technique in improving model performance and its broad applicability, a series of ablation experiments were designed to compare the classification accuracy of an 8-layer deep residual neural network model, with and without knowledge infusion, across different datasets. The aim of these experiments was to gain deeper understanding of the specific impact of knowledge infusion on model performance and its role in various knowledge distillation strategies. The experimental results, summarized in Table 3, reveal that the knowledge infusion technique has a positive impact on model performance. Irrespective of whether the knowledge distillation approach is based on responses (KD), features (FKD), or the de-biased method (DeBKD), the models employing knowledge infusion demonstrate varying degrees of improvement in classification accuracy. Notably, under the DeBKD framework, the incorporation of knowledge infusion leads to a higher increase in accuracy compared with other methods, indicating that the combination of label de-biasing and knowledge infusion can produce a synergistic effect, further optimizing the learning process and outcomes.
| Method | KI | Dataset | |||||||
| D&C | C&H | C&B | |||||||
| Acc (%) | Δ (%) | Acc (%) | Δ (%) | Acc (%) | Δ (%) | ||||
| KD | × | 79.54 | — | 83.78 | — | 82.94 | — | ||
| FKD | × | 79.44 | — | 86.42 | — | 84.21 | — | ||
| DeBKD | × | 79.64 | — | 86.73 | — | 87.11 | — | ||
Table 3. Impact of knowledge infusion (KI) on model performance (
These findings confirm the potential of the knowledge infusion technique as an effective means of enhancing model performance and emphasize its significant value in improving the accuracy and robustness of deep learning models. Through rigorous ablation experiments, we have not only validated the universal applicability of knowledge infusion across multiple distillation frameworks, but also demonstrated its significant effectiveness in enhancing the performance of student models, providing new perspectives and methods for future deep learning research and applications.
5 Conclusion
This study proposes the de-biased knowledge distillation (DeBKD) framework, effectively addressing the performance limitations in deep learning models caused by the model bias during the knowledge distillation process. Experimental results on real datasets demonstrate that the DeBKD framework significantly enhances the performance of student models by improving the quality of knowledge transferred from the teacher model. By reducing the impact of the biases inherent in the teacher model, the DeBKD framework enables student models to more accurately capture and emulate the knowledge of the teacher model, thereby extending the breadth and depth of knowledge distillation applications. Moreover, this study introduces a flexible knowledge infusion technique that can be deployed during the knowledge distillation process. Through innovative bias correction of the teacher model’s misclassified samples, it reduces the misinformation impacting the student model during training. A series of experiments validated the effectiveness of this technique, demonstrating its wide applicability across various deep learning scenarios. This framework provides new insights and tools for the design and optimization of model compression in deep learning models, particularly in enhancing model performance and eliminating biases. In future research, we will further explore the potential of the DeBKD framework in multi-classification task scenarios.
Disclosures
The authors declare no conflicts of interest.
References
[1] LeCun Y., Bengio Y., Hinton G.. Deep learning. Nature, 521, 436-444(2015).
[2] P.F. Zhang, J.S. Duan, Z. Huang, H.Z. Yin, Jointteaching: Learning to refine knowledge f resourceconstrained unsupervised crossmodal retrieval, in: Proc. of the 29th ACM Intl. Conf. on Multimedia, Chengdu, China, 2021, pp. 1517–1525.
[3] Ye G.-H., Yin H.-Z., Chen T., Xu M., Nguyen Q.V.H., Song J.. Personalized on-device e-health analytics with decentralized block coordinate descent. IEEE J. Biomed. Health, 27, 5249-5259(2022).
[4] Y.T. Sun, G.S. Pang, G.H. Ye, T. Chen, X. Hu, H.Z. Yin, Unraveling the ‘anomaly’ in time series anomaly detection: A selfsupervised tridomain solution, in: Proc. of 2024 IEEE 40th Intl. Conf. on Data Engineering, Utrecht, herls, 2024, pp. 981–994.
[5] P.F. Zhang, Z. Huang, X.S. Xu, G.D. Bai, Effective robust adversarial training against data label cruptions, IEEE T. Multimedia (May 2024), DOI: 10.1109TMM.2024.3394677.
[7] C. Buciluǎ, R. Caruana, A. NiculescuMizil, Model compression, in: Proc. of the 12th ACM SIGKDD Intl. Conf. on Knowledge Discovery Data Mining, Philadelphia, USA, 2006, pp. 535–541.
[8] Li Z., Li H.-Y., Meng L.. Model compression for deep neural networks: A survey. Computers, 12, 60:1-22(2023).
[10] H. Pham, M. Guan, B. Zoph, Q. Le, J. Dean, Efficient neural architecture search via parameters sharing, in: Proc. of the 35th Intl. Conf. on Machine Learning, Stockholm, Sweden, 2018, pp. 4095–4104.
[11] G. Hinton, O. Vinyals, J. Dean, Distilling the knowledge in a neural wk [Online]. Available, https:arxiv.gabs1503.02531, March 2015.
[13] M. Phuong, C. Lampert, Towards understing knowledge distillation, in: Proc. of the 36th Intl. Conf. on Machine Learning, Long Beach, USA, 2019, pp. 5142–5151.
[14] X. Cheng, Z.F. Rao, Y.L. Chen, Q.S. Zhang, Explaining knowledge distillation by quantifying the knowledge, in: Proc. of the IEEECVF Conf. on Computer Vision Pattern Recognition, Seattle, USA, 2020, pp. 12922–12932.
[15] A. Gotmare, N.S. Keskar, C.M. Xiong, R. Socher, A closer look at deep learning heuristics: Learning rate restarts, warmup distillation [Online]. Available, https:arxiv.gabs1810.13243, October 2018.
[16] A. Romero, N. Ballas, S.E. Kahou, A. Chassang, C. Gatta, Y. Bengio, Fits: Hints f thin deep s, in: Proc. of the 3rd Intl. Conf. on Learning Representations, San Diego, USA, 2015, pp. 1–13.
[17] K.M. He, X.Y. Zhang, S.Q. Ren, J. Sun, Deep residual learning f image recognition, in: Proc. of the IEEE Conf. on Computer Vision Pattern Recognition, Las Vegas, USA, 2016, pp. 770–778.
[19] P.F. Zhang, Z. Huang, G.D. Bai, X.S. Xu, IDEAL: Highderensemble adaptation wk f learning with noisy labels, in: Proc. of the 30th ACM Intl. Conf. on Multimedia, Lisboa, Ptugal, 2022, pp. 325–333.
[20] Z.X. Xu, P.H. Wei, W.M. Zhang, S.G. Liu, L. Wang, B. Zheng, UKD: Debiasing conversion rate estimation via uncertaintyregularized knowledge distillation, in: Proc. of the ACM Web Conf., Lyon, France, 2022, pp. 2078–2087.
[21] Z.N. Li, Q.T. Wu, F. Nie, J.C. Yan, GraphDE: A generative framewk f debiased learning outofdistribution detection on graphs, in: Proc. of the 36th Intl. Conf. on Neural Infmation Processing Systems, New leans, USA, 2024, pp. 2195:1–14.
[22] Y. Cao, Z.Y. Fang, Y. Wu, D.X. Zhou, Q.Q. Gu, Towards understing the spectral bias of deep learning, in: Proc. of the 30th Intl. Joint Conf. on Artificial Intelligence, Montreal, Canada, 2021, pp. 2205–2211.
[23] Y. Guo, Y. Yang, A. Abbasi, AutoDebias: Debiasing masked language models with automated biased prompts, in: Proc. of the 60th Annu. Meeting of the Association f Computational Linguistics (Volume 1: Long Papers), Dublin, Irel, 2022, pp. 1012–1023.
[24] T. Schnabel, A. Swaminathan, A. Singh, N. Chak, T. Joachims, Recommendations as treatments: Debiasing learning evaluation, in: Proc. of the 33rd Intl. Conf. on Machine Learning, New Yk, USA, 2016, pp. 1670–1679.
[25] J.W. Chen, H.D. Dong, Y. Qiu, et al., AutoDebias: Learning to debias f recommendation, in: Proc. of the 44th Intl. ACM SIGIR Conf. on Research Development in Infmation Retrieval, Virtual Event, 2021, pp. 21–30.
[26] K. Zhou, B.C. Zhang, X. Zhao, J.R. Wen, Debiased contrastive learning of unsupervised sentence representations, in: Proc. of the 60th Annu. Meeting of the Association f Computational Linguistics (Volume 1: Long Papers), Dublin, Irel, 2022, pp. 6120–6130.
[27] B. Heo, J. Kim, S. Yun, H. Park, N. Kwak, J.Y. Choi, A comprehensive overhaul of feature distillation, in: Proc. of the IEEECVF Intl. Conf. on Computer Vision, Seoul, Kea (South), 2019, pp. 1921–1930.
[28] W. Park, D. Kim, Y. Lu, M. Cho, Relational knowledge distillation, in: Proc. of the IEEECVF Conf. on Computer Vision Pattern Recognition, Long Beach, USA, 2019, pp. 3962–3971.
[29] B.R. Zhao, Q. Cui, R.J. Song, Y.Y. Qiu, J.J. Liang, Decoupled knowledge distillation, in: Proc. of the IEEECVF Conf. on Computer Vision Pattern Recognition, New leans, USA, 2022, pp. 11943–11952.
[30] H.L. Zhou, L.C. Song, J.J. Chen, et al., Rethinking soft labels f knowledge distillation: A biasvariance tradeoff perspective, in: Proc. of the 9th Intl. Conf. on Learning Representations, Virtual Event, 2021, pp. 1–15.


Set citation alerts for the article
Please enter your email address

© Copyright 2018-2021 | Chinese Laser Press. All Rights Reserved 沪ICP备15018463号-20